曝DeepSeek-R2将于下月发布 总参数量达1.2万亿
类别:电脑数码
发布时间:2025-04-29 20:34
【太平洋科技快讯】近日,据相关曝料透露,深度求索计划于下个月发布其下一代AI大模型DeepSeek-R2。据悉,该模型在性能和成本上都取得了显著突破,并实现了全产业链的自主可控,有望对现有AI服务市场产生重大影响。
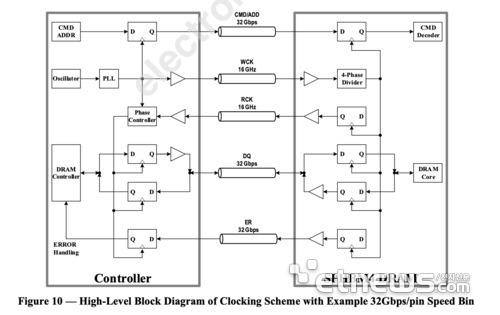
DeepSeek-R2采用了混合专家模型(MoE)架构,并结合了智能门控网络层(Gating Network),以优化高负载推理任务的性能。这种架构通过动态分配计算资源,使得模型能够更灵活、高效地处理复杂任务。此外,DeepSeek-R2的总参数量达到1.2万亿,几乎是上一代DeepSeek-R1的6710亿参数的两倍。
在训练和推理性能上,DeepSeek-R2表现出色。基于华为昇腾910B芯片集群进行训练,该模型在FP16精度下达到512 PetaFLOPS的计算能力,芯片使用效率高达82%,这一性能相当于英伟达上一代A100训练集群的91%。在推理方面,DeepSeek-R2的速度达到每秒320 tokens,比前代模型有显著提升,并且在复杂逻辑推理任务上的准确率提升了83%。
此外,DeepSeek-R2预计将比GPT-4的成本降低97%,这预示着其可能颠覆现有AI服务的定价模式。分析师预计,DeepSeek-R2的定价将显著低于OpenAI的同类产品,这无疑将极大地提升其市场竞争力。































热门优惠券
更多-

- ROTHSCROOSTER旗舰店满49减16
- 有效期至: 2025-01-25
- 立即领取
-
- 萨布森旗舰店满1299减800
- 有效期至: 2025-01-17
- 立即领取
-
- 哲高玩具旗舰店满69减33
- 有效期至: 2025-01-05
- 立即领取
-
- 戴·可·思官方旗舰店满196减27
- 有效期至: 2025-04-01
- 立即领取
-
- 佳婴旗舰店满30减3
- 有效期至: 2025-01-10
- 立即领取
-
- ROTHSCROOSTER旗舰店满19减8
- 有效期至: 2025-01-25
- 立即领取
-
- 荣业官方旗舰店满20减10
- 有效期至: 2025-01-04
- 立即领取
-
- 戴·可·思(Dexter)母婴京东自营旗舰店满48减10
- 有效期至: 2025-01-12
- 立即领取
-
- KOKOROCARE旗舰店满158减100
- 有效期至: 2025-03-28
- 立即领取
-
- RODEL官方旗舰店满59减30
- 有效期至: 2025-01-02
- 立即领取