阿里开源自主AI智能体WebAgent 可模拟人类感知决策和行动
【太平洋科技快讯】5月30日,阿里巴巴在GitHub上开源一款名为WebAgent的自主搜索人工智能(AI)智能体。该智能体具备端到端的自主信息检索与多步推理能力,能够在网络环境中模拟人类的感知、决策和行动。
WebAgent的核心功能在于其强大的自主搜索能力和多步骤逻辑推理能力。它能够主动搜索多个学术数据库,并根据用户需求进行深入分析和总结。此外,WebAgent能够通过多步推理将不同文献中的观点进行整合,最终为用户提供一份全面且精准的研究报告。这种能力使得WebAgent在处理复杂信息检索任务时,表现得如同一位经验丰富的专家。
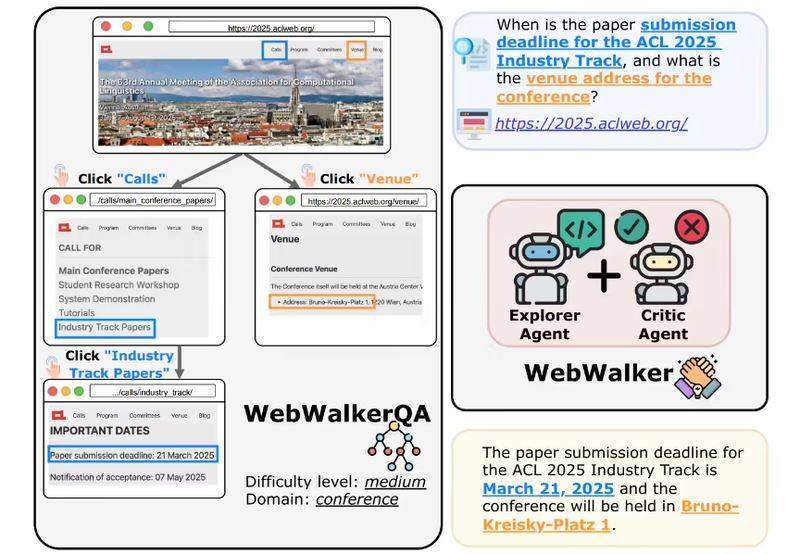
据悉,WebAgent的技术核心在于其训练框架——WebDancer。该框架由四个关键环节组成,从数据构建到训练优化,逐步打造出能够自主完成复杂信息检索任务的智能体。
WebDancer采用了创新的浏览数据构建方法。它通过短推理和长推理两种方式,利用大模型生成简洁的推理路径,或通过推理模型逐步构建复杂的推理过程。这种方法有效解决了传统数据集的局限性,为智能体提供了丰富的训练素材。
在数据准备完成后,WebDancer进入监督微调(SFT)阶段。这一阶段的目标是通过高质量的轨迹数据对智能体进行初始化训练,使其能够适应信息检索任务的格式和环境要求。在SFT过程中,WebDancer将轨迹中的思考、行动和观察内容分别标记,并计算损失函数,以优化模型的参数。为了提高模型的鲁棒性,WebDancer在计算损失时排除了外部反馈的影响,确保模型能够专注于自主决策过程。
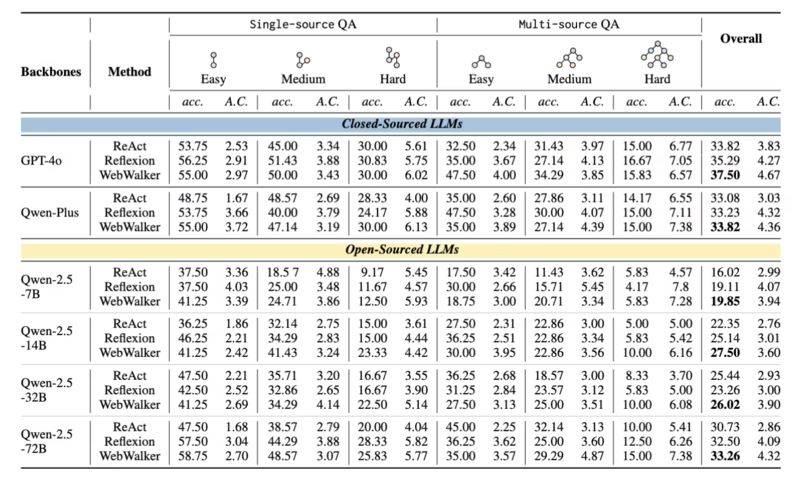
强化学习(RL)阶段是WebDancer框架的关键环节。在这一阶段,智能体通过与环境的交互,学习如何在复杂的任务中做出最优决策。WebDancer采用了DAPO算法,这是一种专门针对智能体训练设计的强化学习算法。DAPO算法通过动态采样机制,有效利用未充分利用的QA对,提高数据效率和策略的鲁棒性。在RL过程中,智能体通过多次尝试和反馈,逐步优化其决策策略,最终实现高效的多步推理和信息检索能力。































热门优惠券
更多-

- ROTHSCROOSTER旗舰店满49减16
- 有效期至: 2025-01-25
- 立即领取
-
- 萨布森旗舰店满1299减800
- 有效期至: 2025-01-17
- 立即领取
-
- 哲高玩具旗舰店满69减33
- 有效期至: 2025-01-05
- 立即领取
-
- 戴·可·思官方旗舰店满196减27
- 有效期至: 2025-04-01
- 立即领取
-
- 佳婴旗舰店满30减3
- 有效期至: 2025-01-10
- 立即领取
-
- ROTHSCROOSTER旗舰店满19减8
- 有效期至: 2025-01-25
- 立即领取
-
- 荣业官方旗舰店满20减10
- 有效期至: 2025-01-04
- 立即领取
-
- 戴·可·思(Dexter)母婴京东自营旗舰店满48减10
- 有效期至: 2025-01-12
- 立即领取
-
- KOKOROCARE旗舰店满158减100
- 有效期至: 2025-03-28
- 立即领取
-
- RODEL官方旗舰店满59减30
- 有效期至: 2025-01-02
- 立即领取