通义 DeepResearch 开源:超越 ChatGPT!
当大家还在惊叹于 AI 真能聊的时候,阿里巴巴通义团队悄然扔出了一枚深水炸弹,推出了通义 DeepResearch 模型。顾名思义,它的目标不再是陪你闲聊,而是要成为一个能帮你深度调研、分析问题、像研究员一样工作的超级 AI 助理。
更关键的是,通义团队这次选择了完全开源!
在这个海外旗舰模型动辄收取高昂费用、处处设限的时代,通义 DeepResearch 将模型、框架、方案一股脑儿全部开放,真正把深度研究这项能力交到了每一位开发者和普通用户的手中。

开源通常意味着在性能上需要做出一些妥协,但通义 DeepResearch 却是个例外。
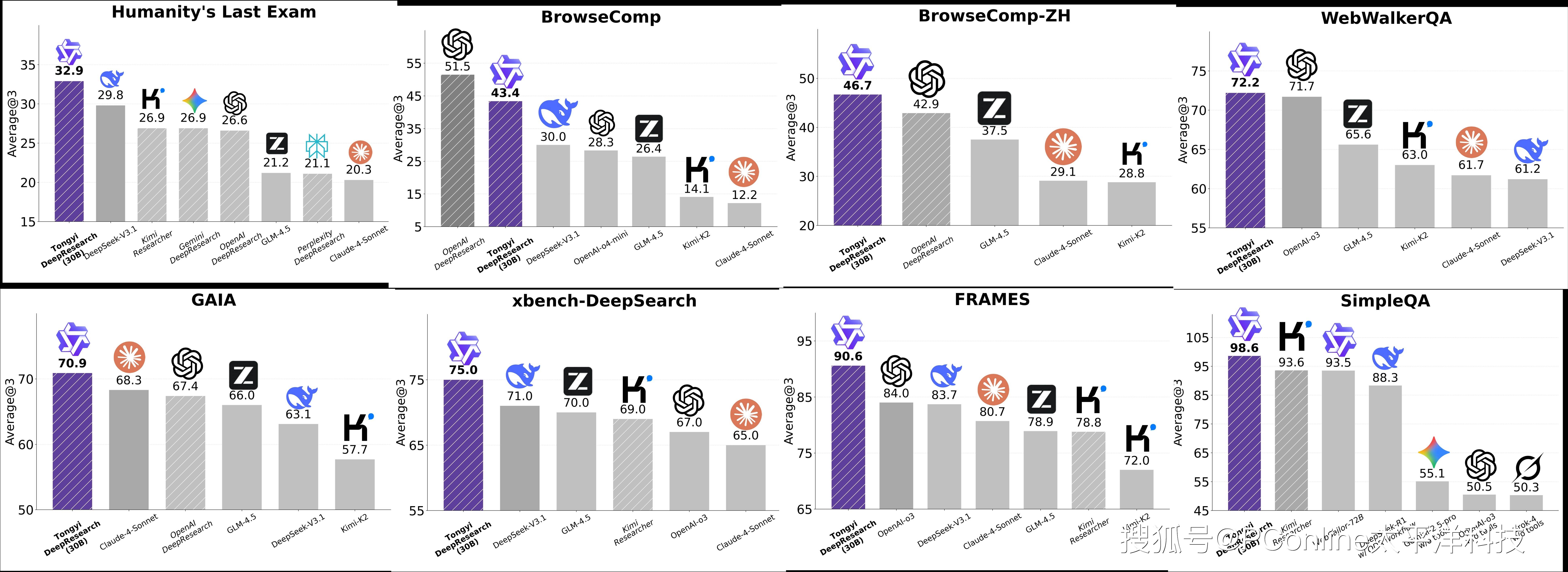
在 GAIA、WebWalkerQA 等多项衡量 AI 深度研究能力的权威 Benchmark(基准测试)上,这款轻量级的 30B 模型不仅取得了 SOTA的成绩,综合能力更是超越了海外某些闭源的旗舰模型。
这意味着,无论是开发者还是企业,现在都可以用更低的成本,获得一个顶尖水平的 AI 研究助理。
那么,通义 DeepResearch 是如何从一个聊天机器人跃迁为研究员的呢?秘诀在于一套创新的数据策略、训练范式和推理模式。
1. 喂给 AI 的不再是白开水,而是营养液
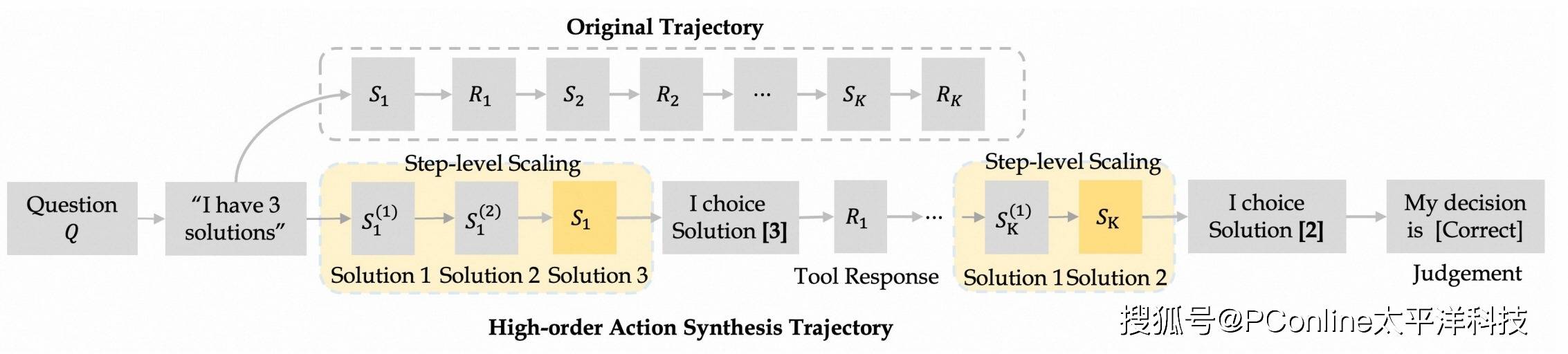
传统 AI 训练依赖大量昂贵的人工标注数据。通义团队另辟蹊径,设计了一套全自动、可循环的合成数据生成方案。
简单来说,他们让 AI 自己去学习如何提出「博士级」的复杂问题,并围绕这些问题去搜集、整理、生成高质量的训练材料。这个过程就像一个正向循环,AI 在解决问题的过程中不断产生新的、更高质量的数据,再用这些数据来训练一个更强的自己,实现了「自我进化」。
2. 像研究员一样思考:ReAct 与 Heavy 两种模式
为了应对不同复杂度的任务,DeepResearch 具备两种工作模式:
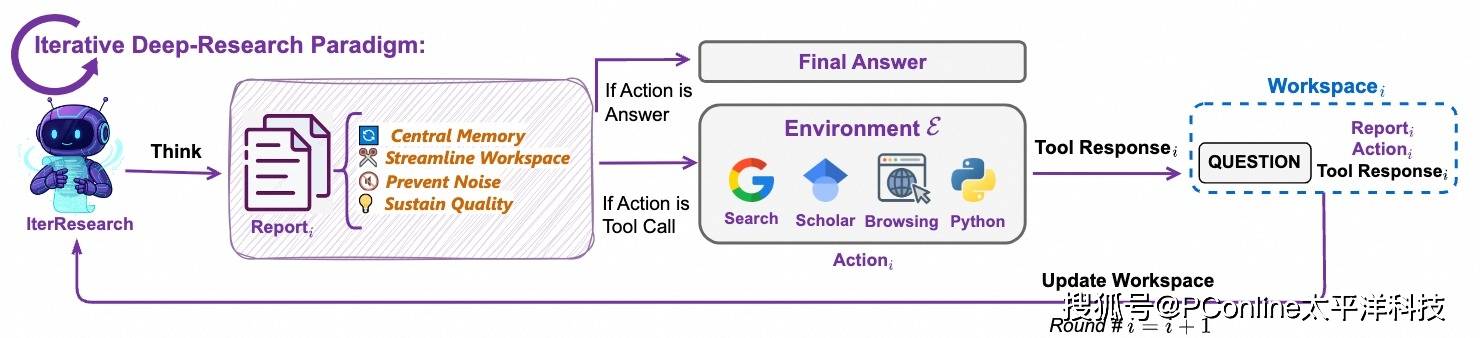
ReAct 模式:这是它的基础模式,遵循「思考-行动-观察」的经典循环,足以高效处理大部分研究任务。
Heavy 模式(深度模式):当遇到极其复杂的长期研究课题时,该模式会启动。它独创了 IterResearch 范式,将一个庞大的研究任务拆解成多个「研究轮次」。在每一轮中,AI 只聚焦于当前最核心的信息,完成分析和整合后,再带着精炼的结论进入下一轮。这有效避免了在海量信息中迷失方向,确保了长期任务的推理质量和认知焦点。更有趣的是,它还能让多个 AI 分身并行研究同一问题,最后综合报告,得出更全面的结论。
3. 完整的 AI 养成流水线
通义团队打通了从增量预训练(CPT)、监督微调(SFT)冷启动,到强化学习(RL)的端到端全流程,形成了一套全新的 Agent 训练范式。尤其在强化学习阶段,他们不仅在算法上进行了优化,还搭建了一套包括模拟训练环境、稳定工具调用沙盒在内的高效基础设施,让 AI 能在一个稳定、可控的环境中不断试错,持续提升能力。

通义 DeepResearch 并非停留在实验室里的概念,它已经开始在实际业务中大显身手。
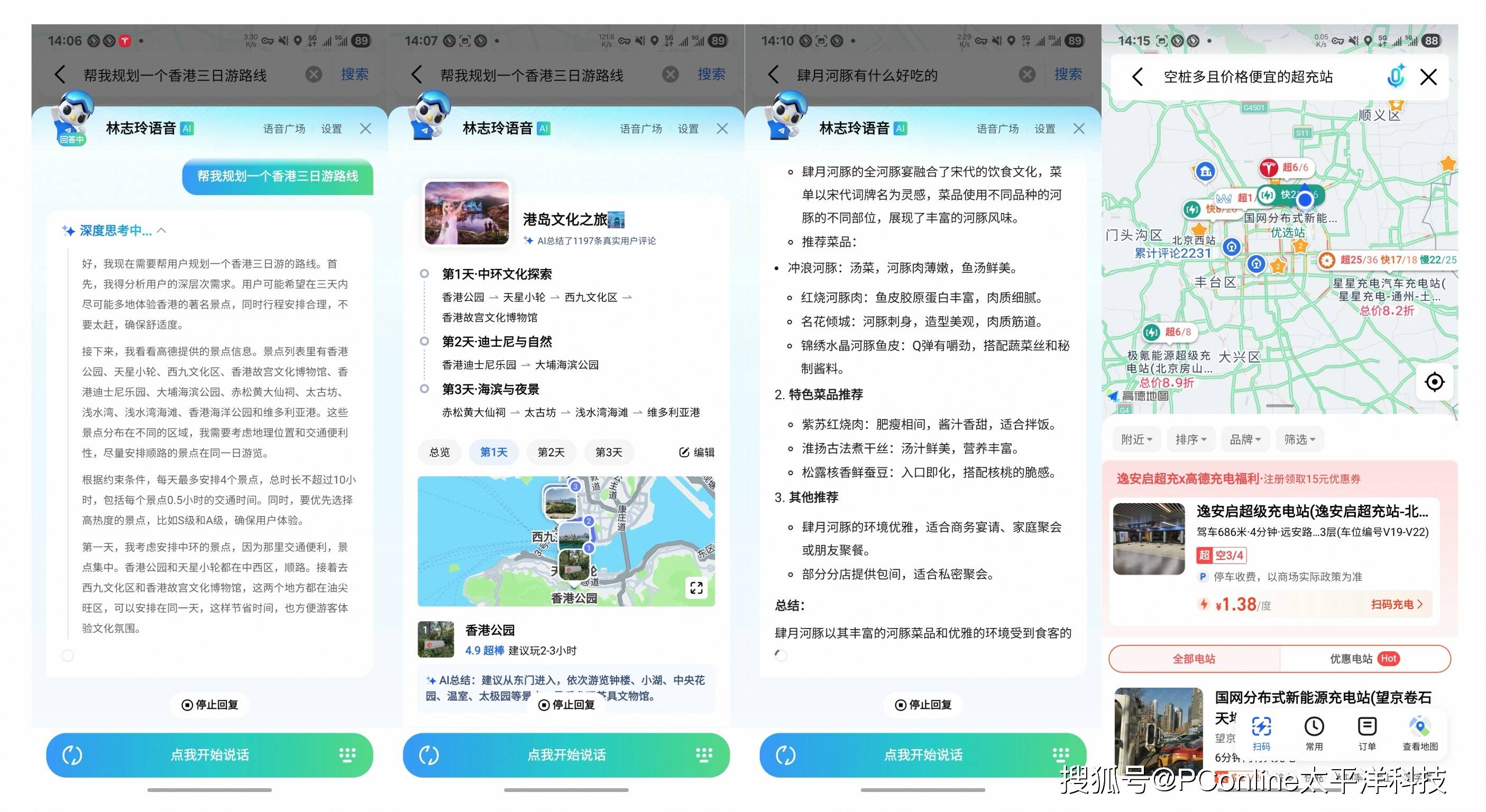
高德地图:当你向高德小德助手提出一个复杂的出行规划问题,比如「找一个离我最近、评分高、适合带孩子玩的亲子餐厅,并规划一条不堵车的路线」,背后就是 DeepResearch 在进行多步推理和工具调用,为你提供精准答案。
通义法睿:作为法律智能体,DeepResearch 的能力让它在处理复杂法律咨询时如虎添翼。它能快速检索相关案例和法条,结合权威观点,生成一份逻辑清晰、有据可查的法律分析报告,其专业性在业内处于领先地位。
通义 DeepResearch 的全面开源,无疑为 AI Agent 的发展注入了一剂强心针。它证明了 AI 的能力边界远不止于流畅对话,而是能够深入复杂领域,成为人类强大的研究工具。当顶尖的研究能力不再是少数人的专利,我们有理由期待一个由 AI 驱动的,更具创造力和洞察力的新时代的到来。































热门优惠券
更多-

- ROTHSCROOSTER旗舰店满49减16
- 有效期至: 2025-01-25
- 立即领取
-
- 萨布森旗舰店满1299减800
- 有效期至: 2025-01-17
- 立即领取
-
- 哲高玩具旗舰店满69减33
- 有效期至: 2025-01-05
- 立即领取
-
- 戴·可·思官方旗舰店满196减27
- 有效期至: 2025-04-01
- 立即领取
-
- 佳婴旗舰店满30减3
- 有效期至: 2025-01-10
- 立即领取
-
- ROTHSCROOSTER旗舰店满19减8
- 有效期至: 2025-01-25
- 立即领取
-
- 荣业官方旗舰店满20减10
- 有效期至: 2025-01-04
- 立即领取
-
- 戴·可·思(Dexter)母婴京东自营旗舰店满48减10
- 有效期至: 2025-01-12
- 立即领取
-
- KOKOROCARE旗舰店满158减100
- 有效期至: 2025-03-28
- 立即领取
-
- RODEL官方旗舰店满59减30
- 有效期至: 2025-01-02
- 立即领取