DeepSeek联合清华推AI对齐技术SPCT 降低训练成本并提升性能
类别:电脑数码
发布时间:2025-04-08 21:24
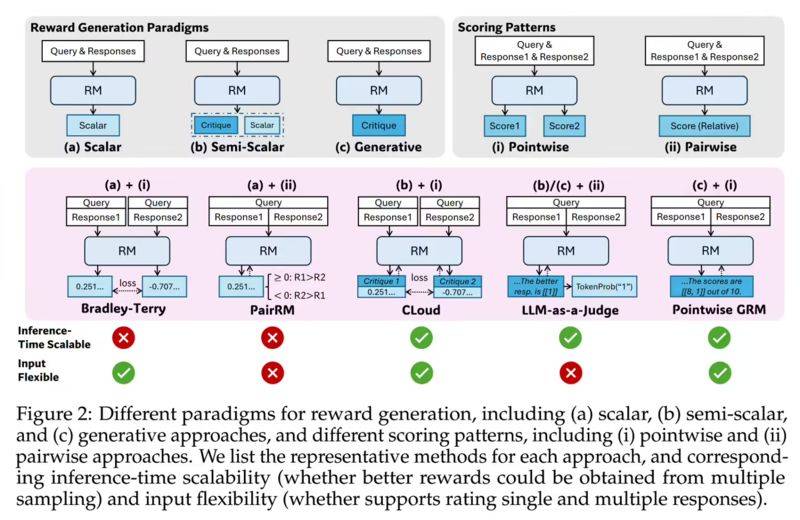
SPCT技术基于“原则合成-响应生成-批判过滤-原则优化”的递归架构,使AI模型在推理过程中能够实时自我修正,确保输出结果的准确性和可靠性。
拒绝式微调冷启动阶段:在此阶段,生成模型(GRM)被训练以适应各种输入类型,并学会以正确格式生成原则和点评内容。
基于规则的在线强化学习阶段:通过引入规则奖励机制,模型在这一阶段不断优化其生成的原则和点评内容,从而提升推理阶段的可扩展性。
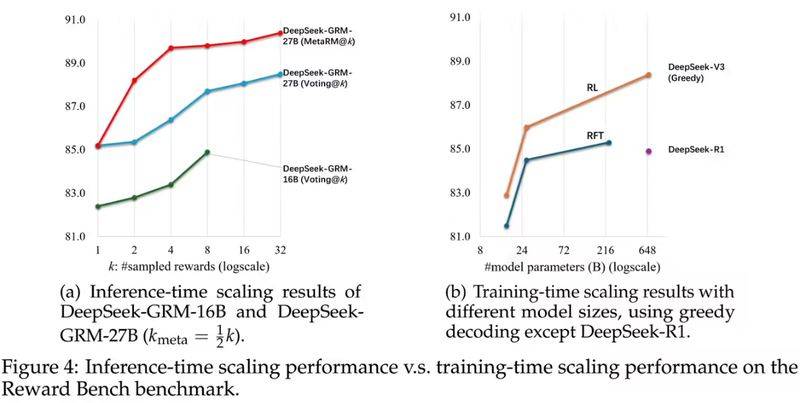
在测试中,配备270亿参数的DeepSeek-GRM模型展现了惊人的性能,通过每查询32次采样的推理计算,达到了与671B规模模型相媲美的水平。此外,该模型采用的硬件感知设计融合了混合专家系统(MoE),支持128k token的上下文窗口,单查询延迟仅为1.4秒。
SPCT技术显著降低了高性能AI模型的部署门槛。以DeepSeek-GRM模型为例,其训练成本仅为1.2万美元,相较于同类模型动辄数百万美元的成本,实现了极大的成本优化。与OpenAI的GPT-4o模型相比,DeepSeek-GRM的成本仅为后者的1/525。
此外,SPCT技术还减少了90%的人工标注需求,大幅降低了人力成本。相较于传统方法,SPCT的能耗降低了73%,更加环保节能。由于其出色的性能和低延迟设计,SPCT技术为实时机器人控制等动态场景提供了新的可能性。
































热门优惠券
更多-

- ROTHSCROOSTER旗舰店满49减16
- 有效期至: 2025-01-25
- 立即领取
-
- 萨布森旗舰店满1299减800
- 有效期至: 2025-01-17
- 立即领取
-
- 哲高玩具旗舰店满69减33
- 有效期至: 2025-01-05
- 立即领取
-
- 戴·可·思官方旗舰店满196减27
- 有效期至: 2025-04-01
- 立即领取
-
- 佳婴旗舰店满30减3
- 有效期至: 2025-01-10
- 立即领取
-
- ROTHSCROOSTER旗舰店满19减8
- 有效期至: 2025-01-25
- 立即领取
-
- 荣业官方旗舰店满20减10
- 有效期至: 2025-01-04
- 立即领取
-
- 戴·可·思(Dexter)母婴京东自营旗舰店满48减10
- 有效期至: 2025-01-12
- 立即领取
-
- KOKOROCARE旗舰店满158减100
- 有效期至: 2025-03-28
- 立即领取
-
- RODEL官方旗舰店满59减30
- 有效期至: 2025-01-02
- 立即领取