极摩客 EVO-X2 mini :一台桌面Mini主机,打通AI本地部署
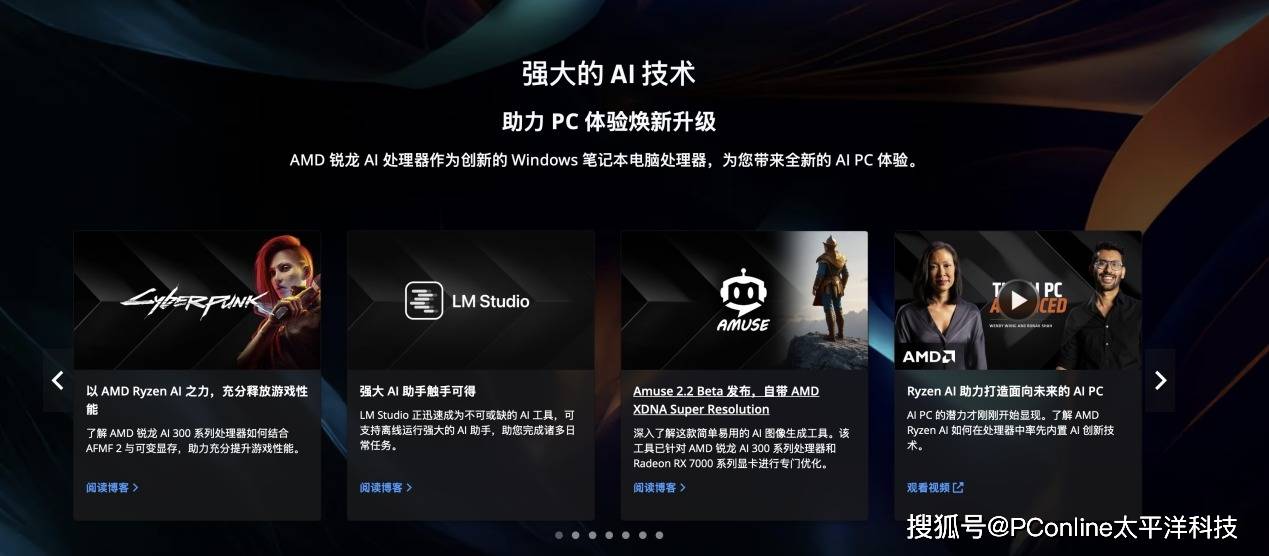
在AI全面触达各行各业的今天,从初学者到开发者、从极客到内容创作者,越来越多的人开始尝试将大模型部署在本地设备上,从而摆脱云端服务的限制,实现低延迟、更私密、可控的AI应用体验。
而在2025年,随着AMD推出基于Strix Halo架构的锐龙 AI Max+ 395平台,这一目标开始走入现实。这次我们体验的极摩客 EVO-X2 桌面Mini AI主机,就搭载了这颗旗舰级APU,以及128GB LPDDR5X内存和2TB PCIe 4.0 SSD。

当然,极摩客 EVO-X2 Mini 的定位不止于普通主机,它更像是一套完整的本地 AI 实验平台。其目标用户涵盖AI相关的学生、初创团队、独立开发者以及内容创作者,旨在让他们能够在本地进行模型适配、验证和应用开发工作。过去许多必须“上云”才能完成的AI任务,现在在一台Windows桌面Mini AI工作站机器上就能实现:
本地运行大模型:支持在本地跑 32B~70200B以上 参数规模的量化语言模型,大幅降低对云端GPU的依赖。
多模态AI推理:不仅可以运行文本生成,还能跑图文生成、图像识别、语音识别等多模态模型,满足文本、图像、语音多方面的AI创作需求。
多模型并行处理:可同时加载多个模型共同运行,如同时启动语言模型+图像生成+语音转写,随时快速切换,响应依然流畅。
通过这样的平台化设计,极摩客EVO-X2 Mini 解决了过去「只能上云」的痛点,让开发者在本地就可完成完整的AI开发流程:无需担心云服务的计费和限流,也无需担心敏感数据上传云端的风险。本地部署意味着没有 Token 调用限制,数据完全掌握在自己手中,迭代调试也可以离线完成。这款产品真正实现了AI开发从云端回归本地的一次飞跃。
今天我们就从外观设计、基准性能、本地部署大模型测试、多模态生成体验几个维度,全方位评估这台“桌面Mini AI超算中心”的真正实力。

设计语言:极简科幻,桌面即是工作站

作为一款面向AI开发的桌面Mini工作站,极摩客 EVO-X2 Mini 在外观设计上强调“小体积,大能量”。整机采用一体化的“再生铝”合金机身结构,银黑配色的极简工业风,小巧的机身尺寸约193×186×77 mm,非常适合摆放在工作室、实验室乃至宿舍的桌面上。

全铝外壳不仅保证了坚固质感,也有助于散热稳定,高负载运行时机身仍能保持良好温控。
EVO-X2 Mini 的接口扩展也相当丰富,方便开发者搭建本地服务器或高性能工作流。机身前面板提供了USB4(40Gbps)高速接口、USB 3.2 Gen2接口×2、SD卡槽和音频接口,以及性能模式切换键等;

背面则配备了2.5G以太网口、更多USB接口(包括另一组USB4和3组USB-A)、HDMI 2.1、DP 1.4视频输出等。

这些接口意味着开发者可以灵活连接外接显卡(通过USB4接口的外置GPU坞站)、AI加速模块、高速存储阵列甚至多显示器,扩展出媲美服务器的I/O能力。在如此小巧的机身中集成如此全面的功能接口,充分体现了对开发者使用场景的友好设计——无需占用机房空间,在桌面即可搭建属于自己的AI超级工作站。
二、性能测试:CPU、GPU、存储全面释放
极摩客EVO-X2 mini核心搭载了AMD 锐龙 AI Max+ 395 APU,是当前AMD面向AI PC推出的最强桌面平台之一。

它使用16颗超大核心32线程的Zen 5 CPU架构,主频高达5.1GHz,集成40 CU的RDNA 3.5 GPU,型号为Radeon 8060S,配备XDNA 2架构的NPU,AI算力高达到50+ TOPS,总算力126 TOPS,支持最大128GB LPDDR5X内存,内存带宽高达256GB/s。接下来我们对这台机器进行基础测试。

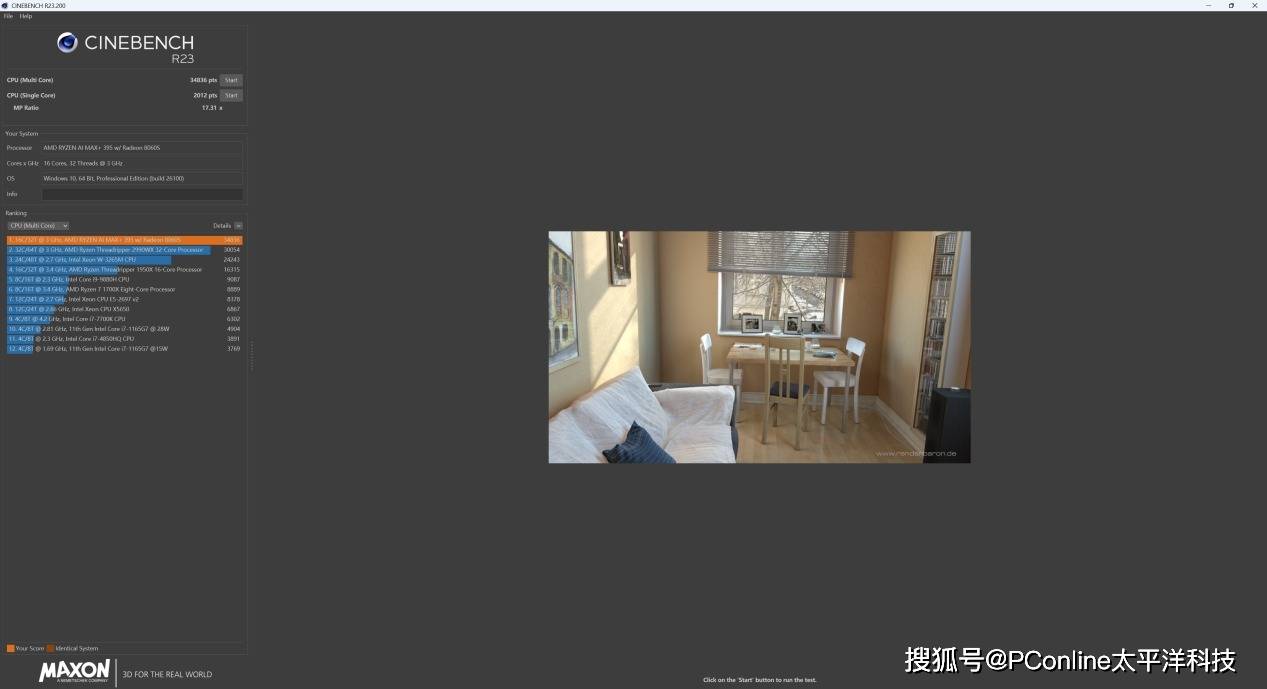
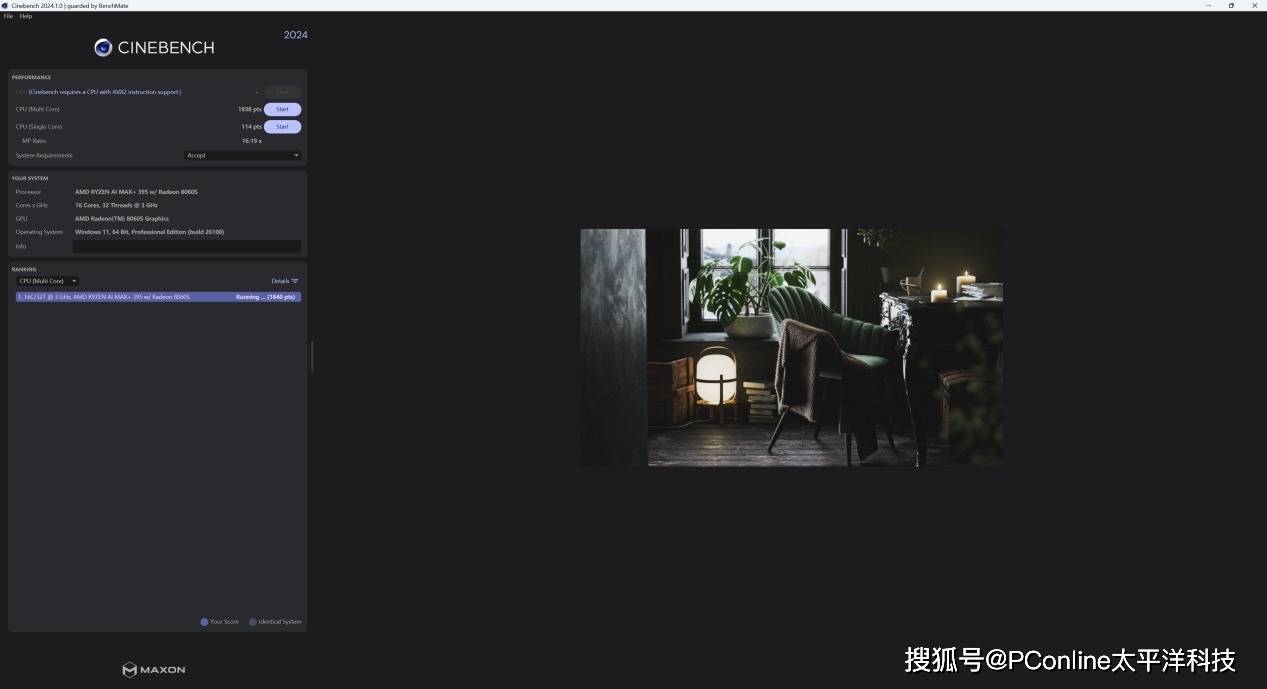
在CineBench R23的测试中,CPU单核得分为2012分,多核得分为34836分。在CineBench R24的测试中,它拿到了单核得分113114分,多核得分1838分,这样的分数表现证明这块CPU表现可以稳稳媲美桌面级旗舰平台,应对大模型加载、多线程推理毫无压力。
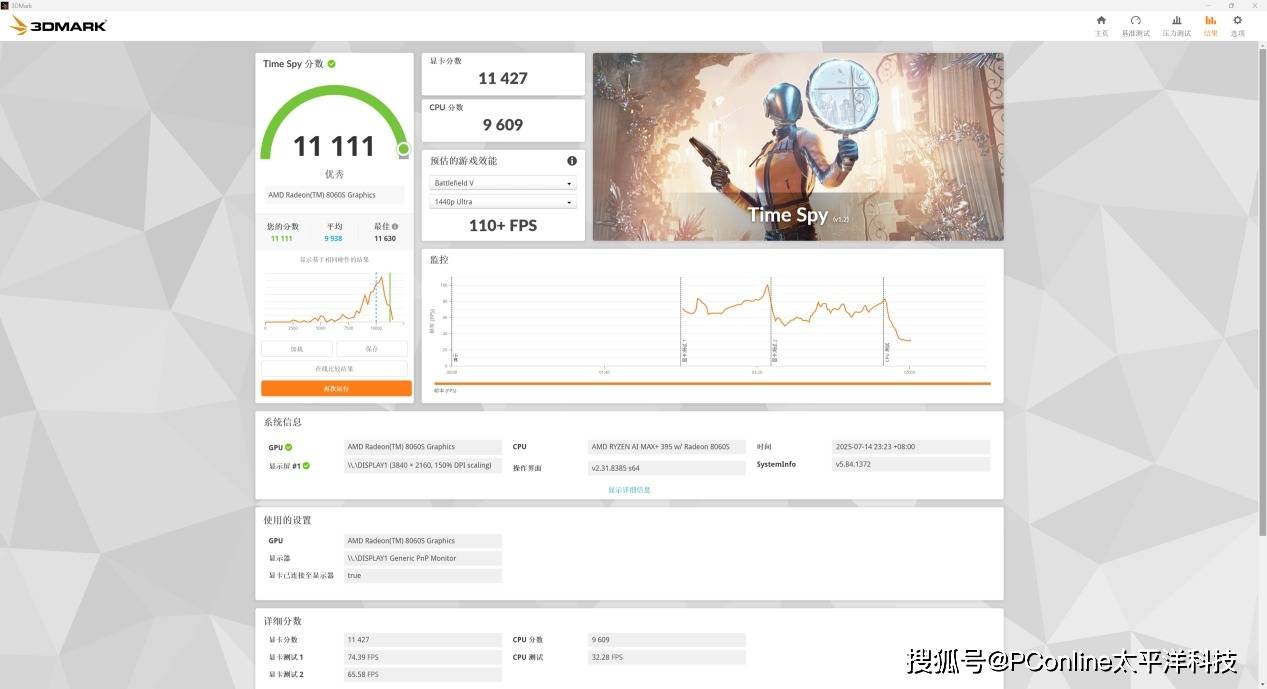
在3Dmark图形计算任务中,Radeon 8060S 表现超越传统核集显甚至追平中端独显,TimeSpy显卡成绩为11427,综合成绩11111分。
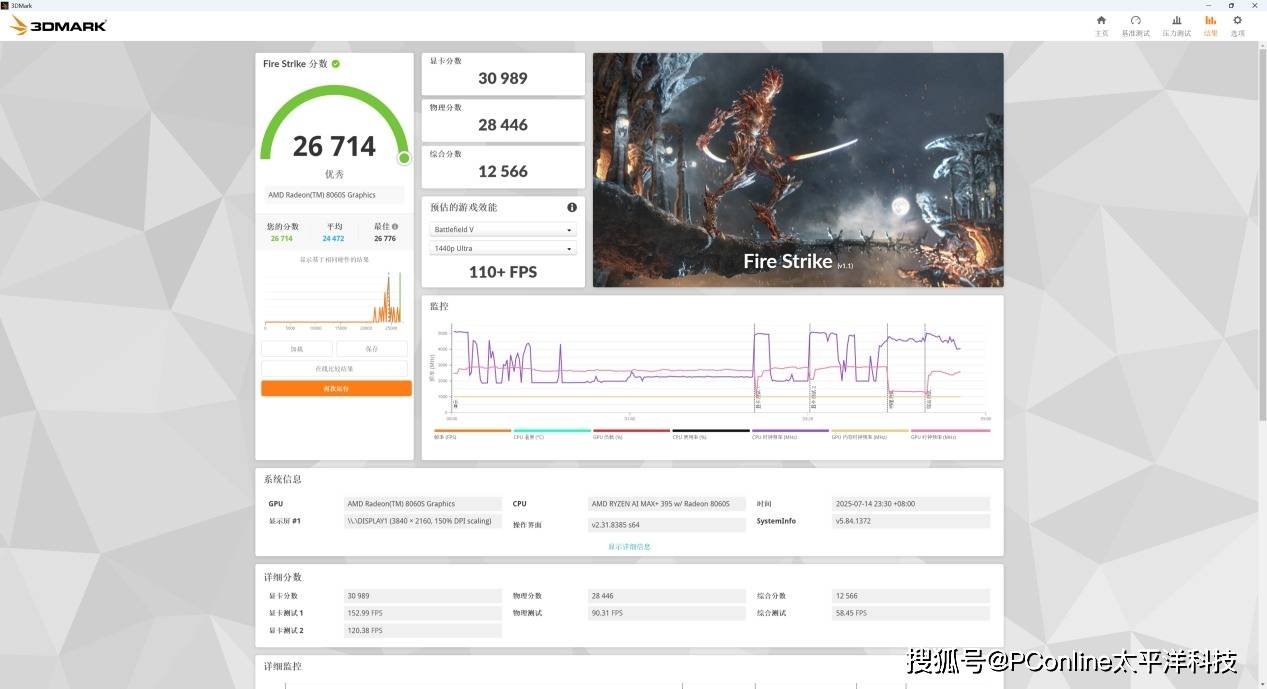
在Fire Strike测试任务中,显卡成绩为30989分,综合成绩26714分。
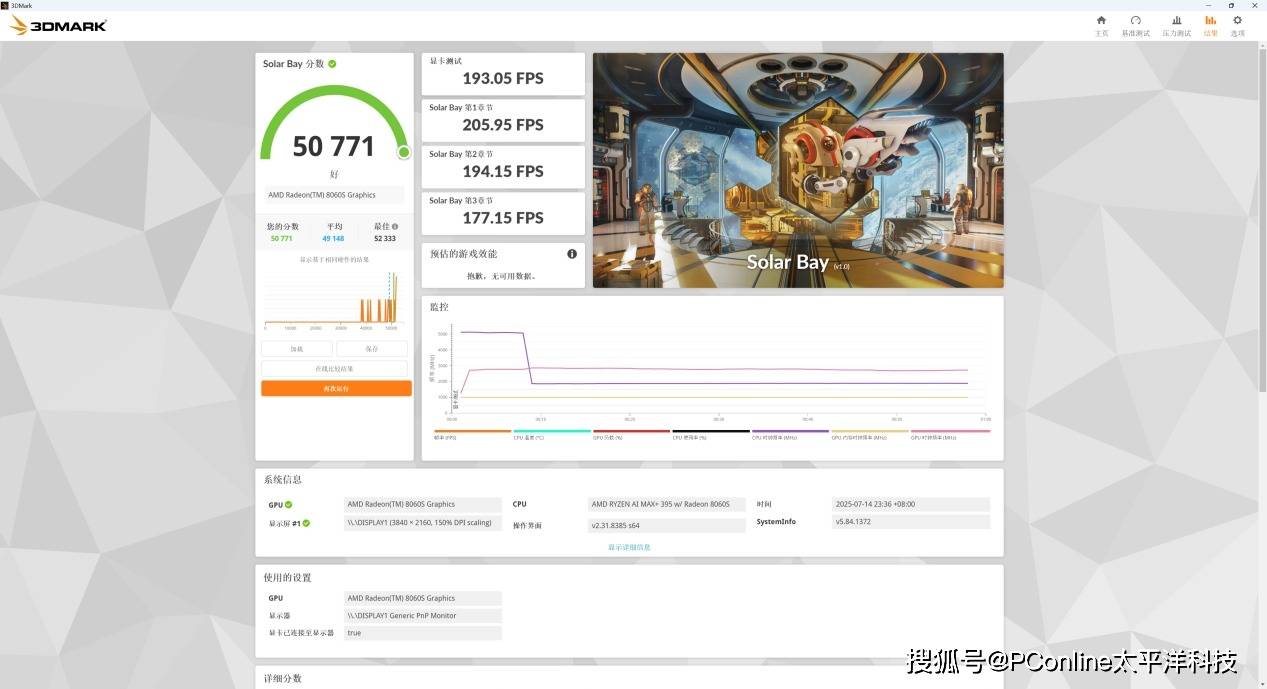
而在Solar Bay中,则保持了193FPS流畅输出,这证明了AMD Radeon 8060S能够为图像/视频类AI模型提供了稳定基础。
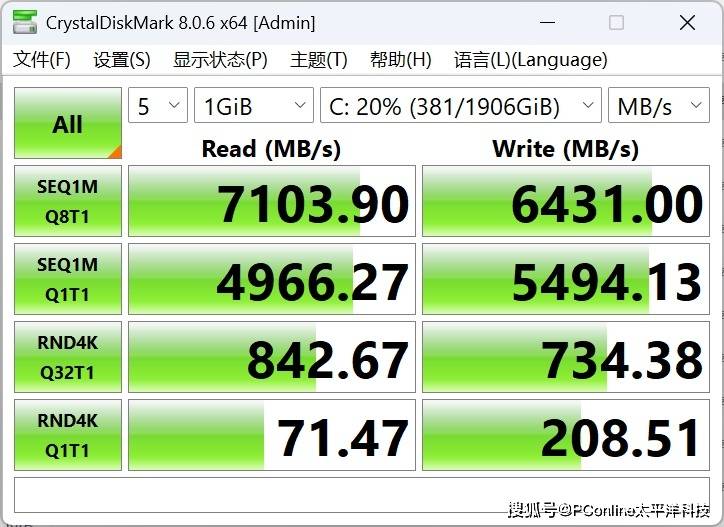
同时我们还使用 CrystalDiskMark 对它的存储带宽进行测试,它的顺序读取:7103.90 MB/s顺序写入:6431.00 MB/s,这样的超高速SSD让大模型文件加载、初始化过程几乎没有等待时间,大幅提升开发迭代效率。
三、大模型实测:从Qwen3-235B到DeepSeek V3,真正可用的“本地AI”
光看跑分还不够,关键还是得看一台机器能不能把真正的把大模型跑起来。过去像 70B、32B 这种级别的语言模型,或者像 Flux 这样的图像生成模型,基本只能靠动辄几万块的云服务器来撑起。
但 AMD Ryzen 锐龙AI Max+ 395,算力强、内存大,支持统一内存技术,可以将96GB内存划归显存使用,还能灵活调度 CPU、GPU 和 NPU,让很多原本只能云上跑的模型,在本地也能稳定高速地运行。而且对 AI 初学者或者入门级开发者来说,这也意味着门槛一下降下来了——以前不敢想的事,现在一台小主机就能干。

首先我们使用LM Studio,部署了来自AMD AI生态伙伴模优优团队优化过的最新大模型Qwen3-235B,模型加载后占用了约60GB内存。
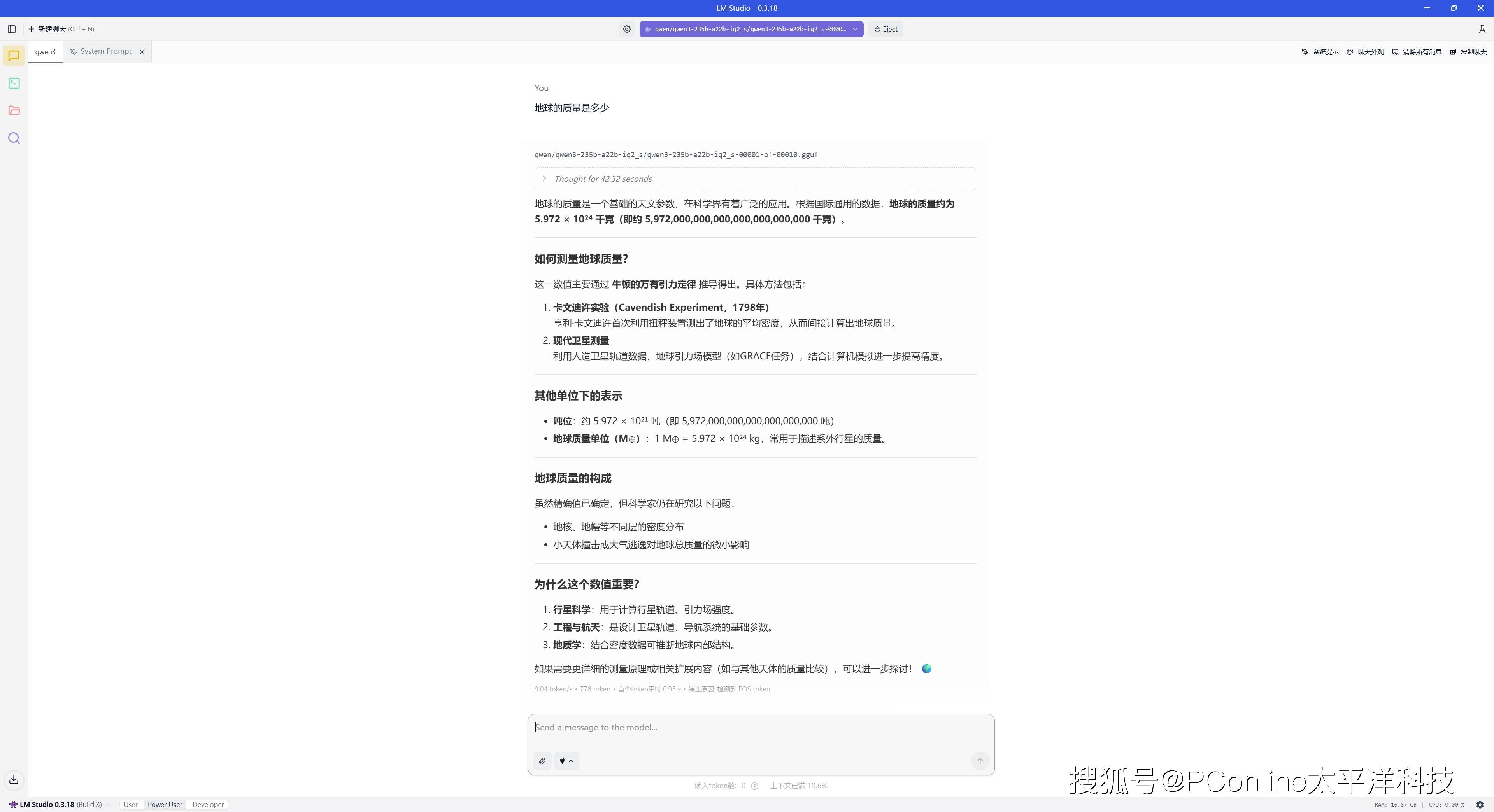

我们在模型上提问了几个问题,例如计算地球的质量,从回答的过程和结果来看逻辑缜密,一共输出了778tokens960tokens,速度为9.0412.05 tok/sec,首个token输出延迟为0.925s。
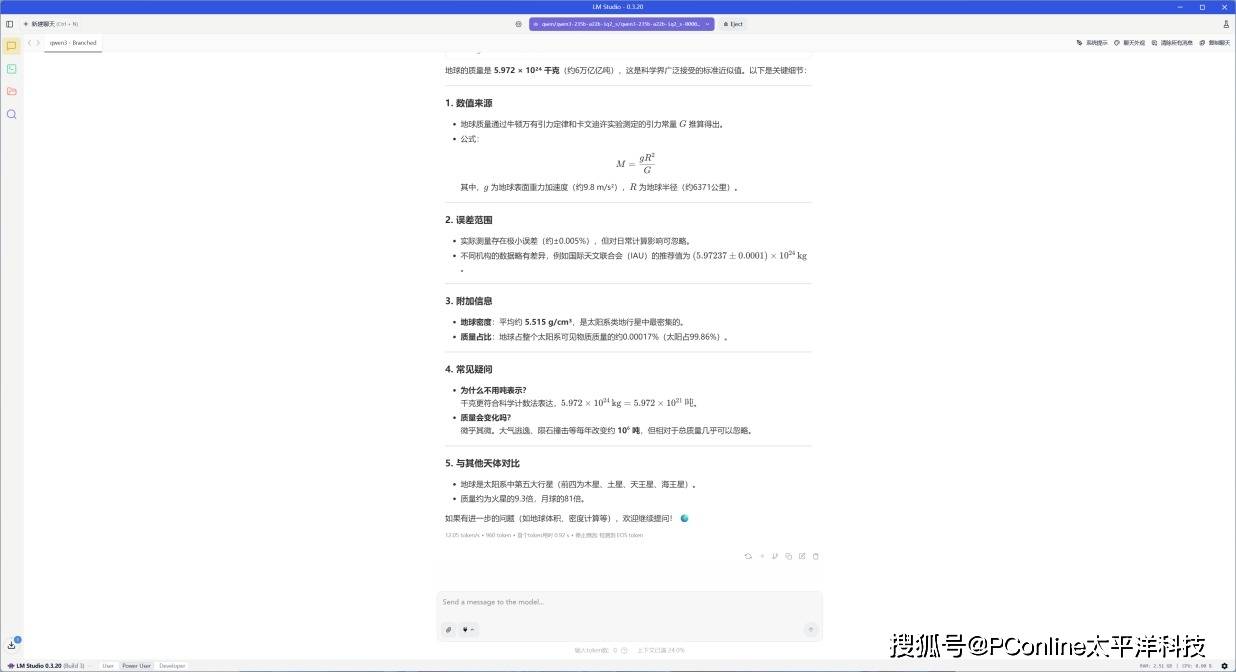

接下来我们稍微上了点强度,提问了AI测试中的中等难度数学题:“1个苹果=2个梨,3个梨=4个橙子,6个橙子=7个香蕉,56个香蕉等于多少个苹果?”。这道题是数量关系,但是需要做公倍数的推理。
在经过6分40秒后模型给出答案,一共输出了2526 tokens,速度为10.10 tok/sec,首个token输出延迟为2.87s。
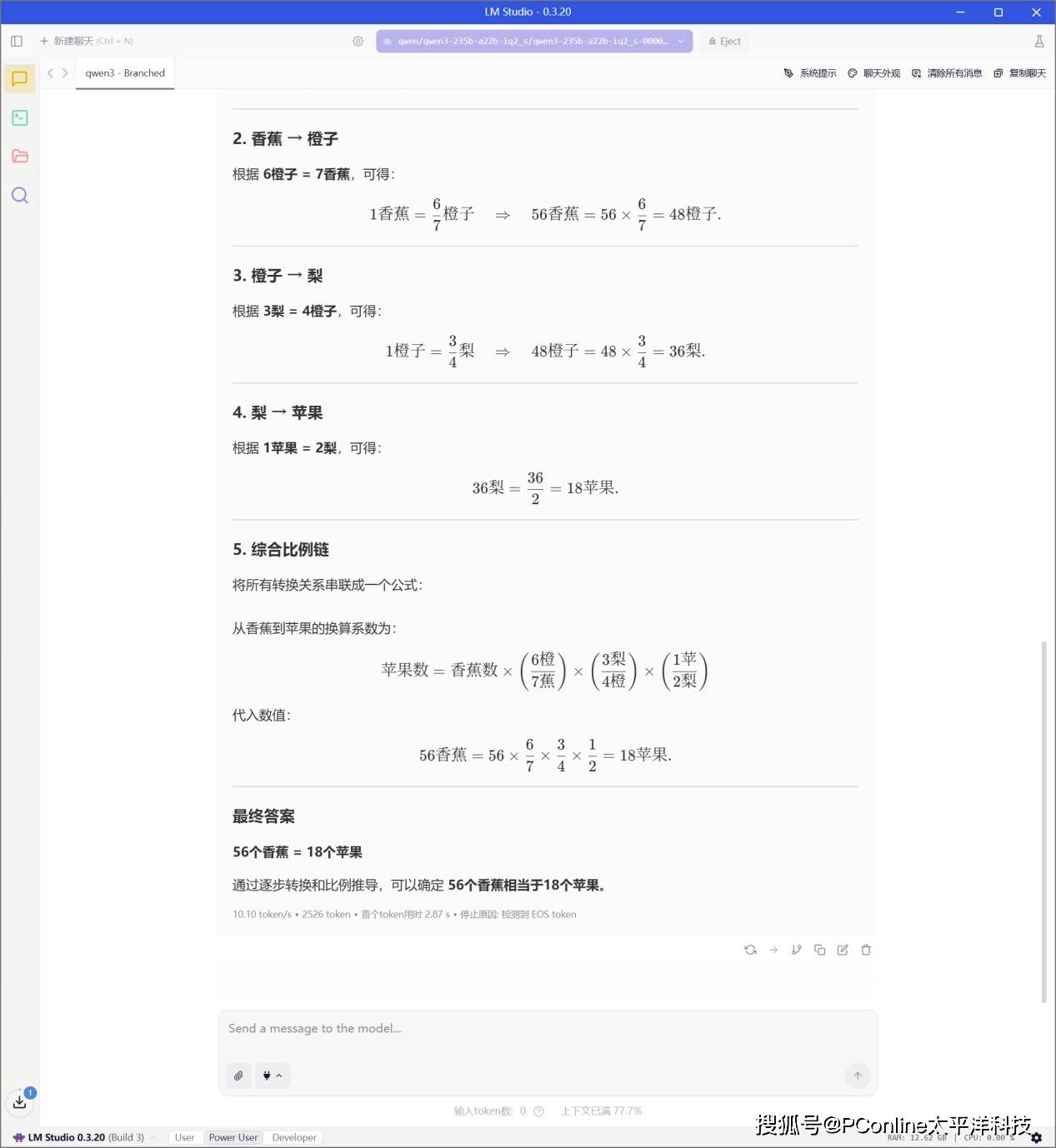
同时我们观察在实际推理时的硬件表现,GPU负载22100%、CPU负载567%、内存负载3772%,所有问题响应速度快,运行过程稳定。能在一台小型主机上跑动如此规模的LLM,充分证明了Strix Halo架构强大的内存带宽和异构算力。
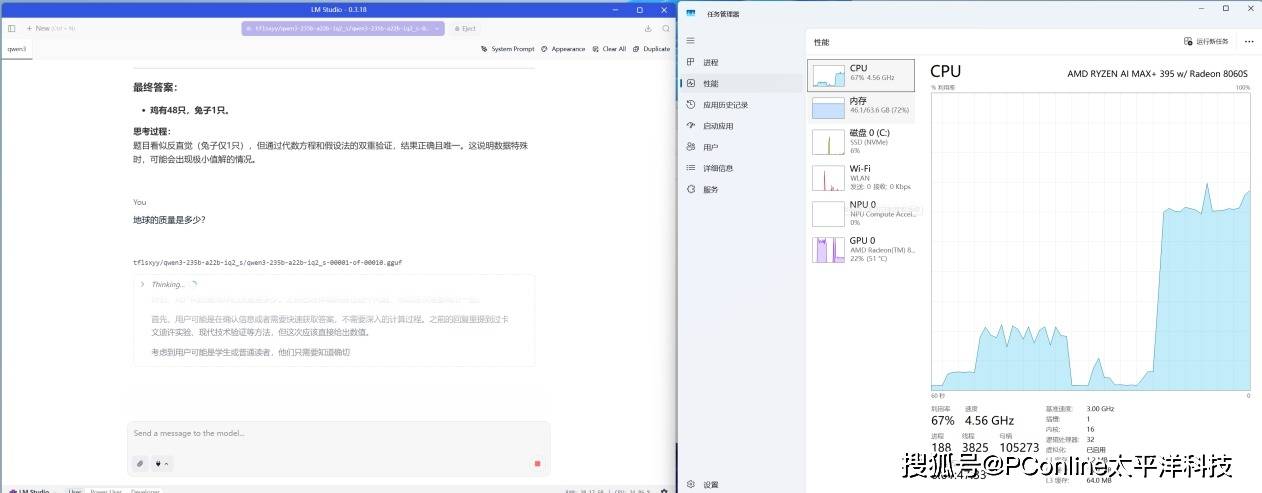
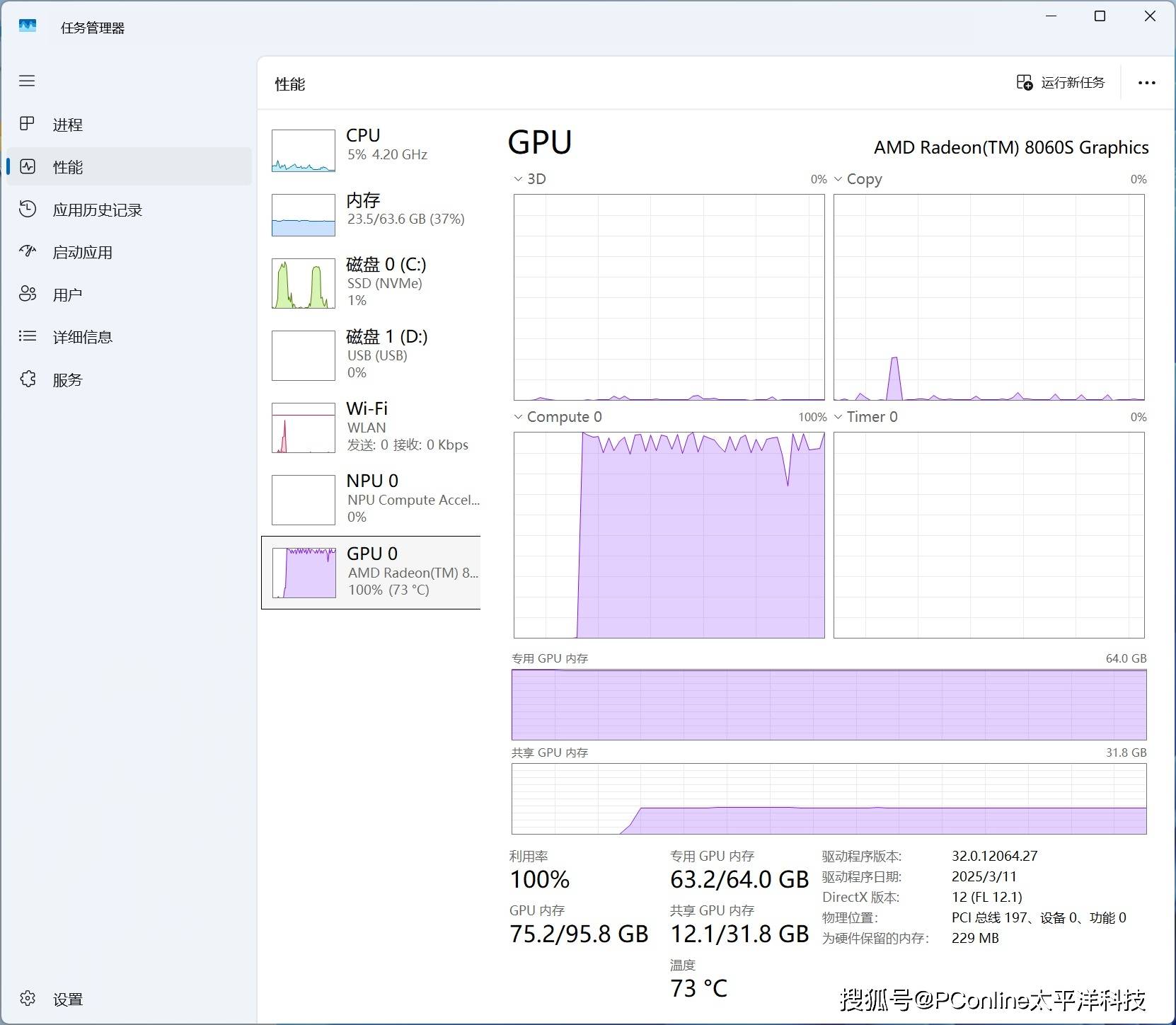
之后我们重新部署了同样量级的DeepSeek-V3,来看看它的表现如何。
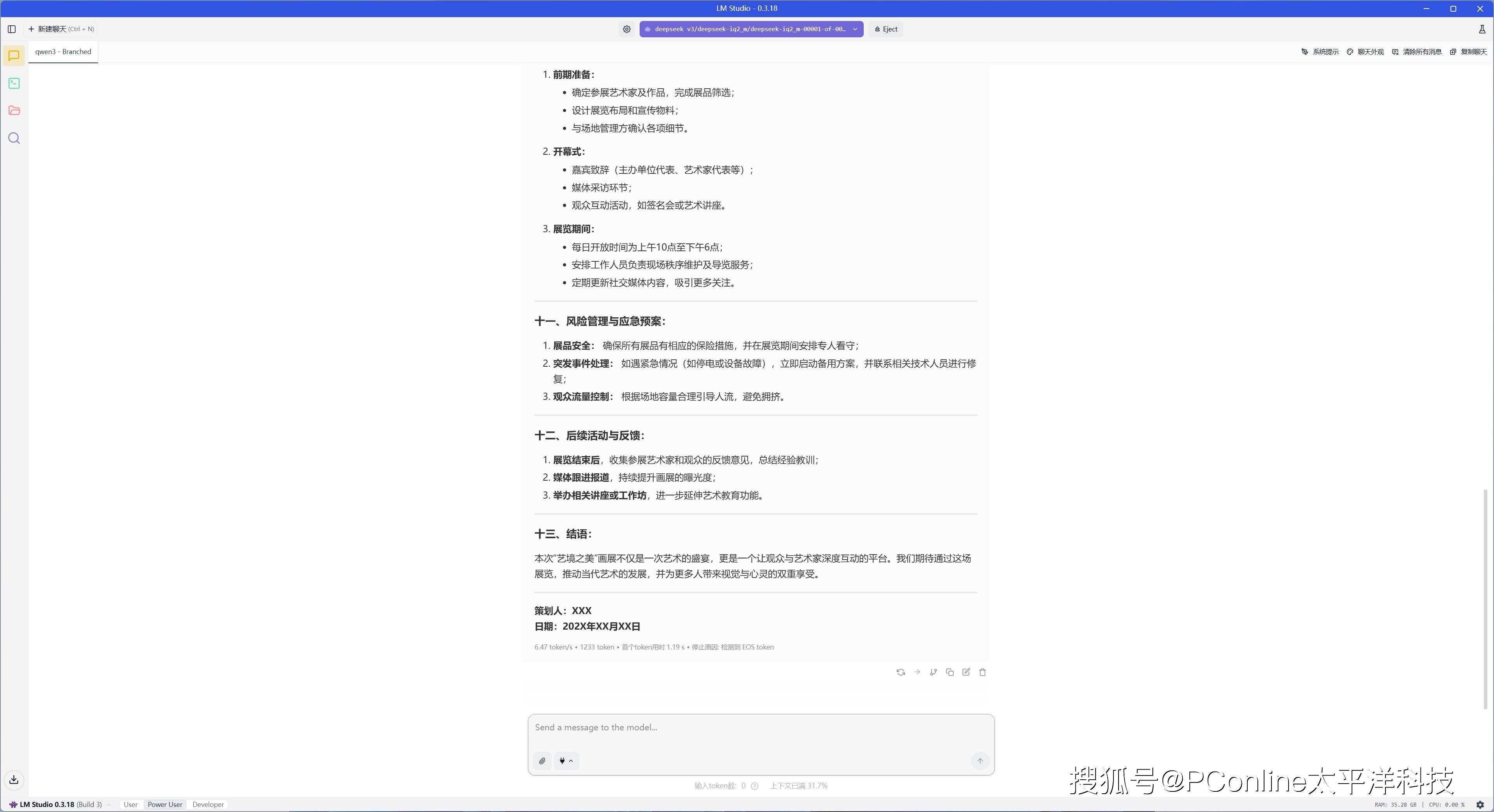
我们让DeepSeek来进行一场画展策划案,能够看到它的执行方案十分清晰,本次回答总计输出1233 tokens,速度为6.47 tok/s,首个token延迟为1.19s。
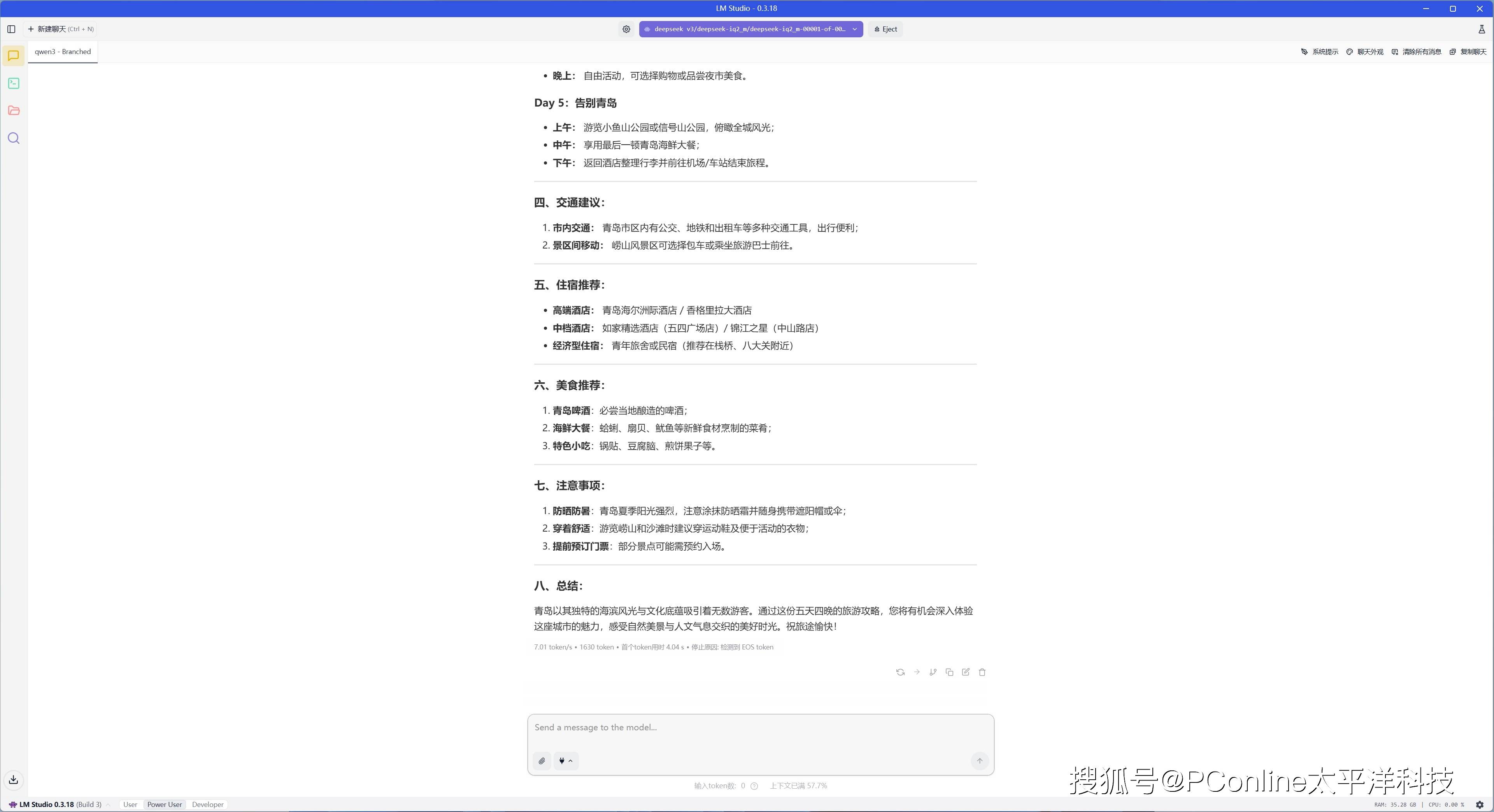
之后我们又让DeepSeek给出一份旅行计划,它同样给出了十分不错的答案。本次回答总计输出1630 tokens,速度为7.01 tok/s,首个token延迟为4.04s。
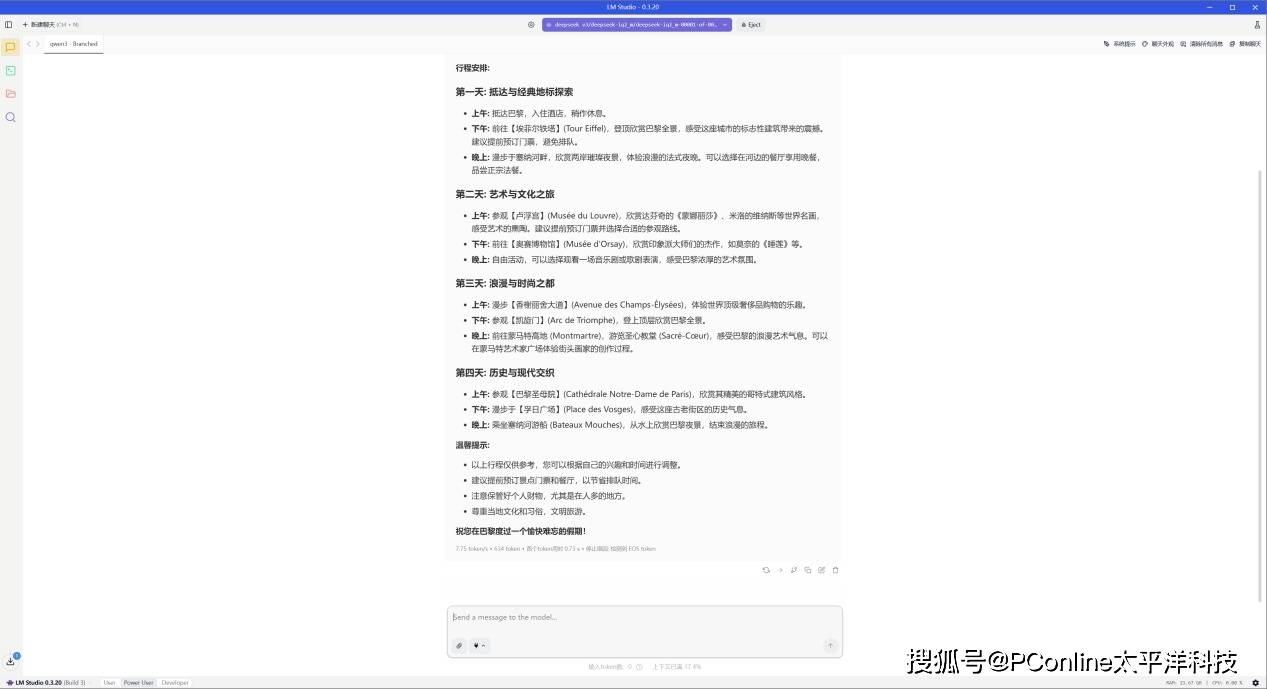
之后我们又让DeepSeek给出一份旅行计划,它同样给出了十分不错的答案。本次回答总计输出634 tokens,速度为7.75 tok/s,首个token延迟为0.73s。
整体来看,无论是面对参数体量庞大的 Qwen3-235B,还是处理偏实用场景导向的 DeepSeek 模型,EVO-X2 Mini 都展现出了稳定、流畅的推理表现,关键是还能在桌面端轻松实现。硬件层面,Strix Halo 架构不光是“能跑”,而是且跑得住、跑得稳,这种来自 AMD 的异构算力整合,确实让本地 AI 部署这件事,离“普通开发者”更近了一大步。
四、图像 & 视频模型部署:Amuse 本地多模态体验

除了语言模型,EVO-X2 Mini 在图像、视频等创意类模型的应用上也非常值得关注。接下来我们使用 Amuse 3.0 平台来进行测试,该平台整合了包括 Flux(文生图) 和locomotion(文生视频) 在内的一系列生成式模型。
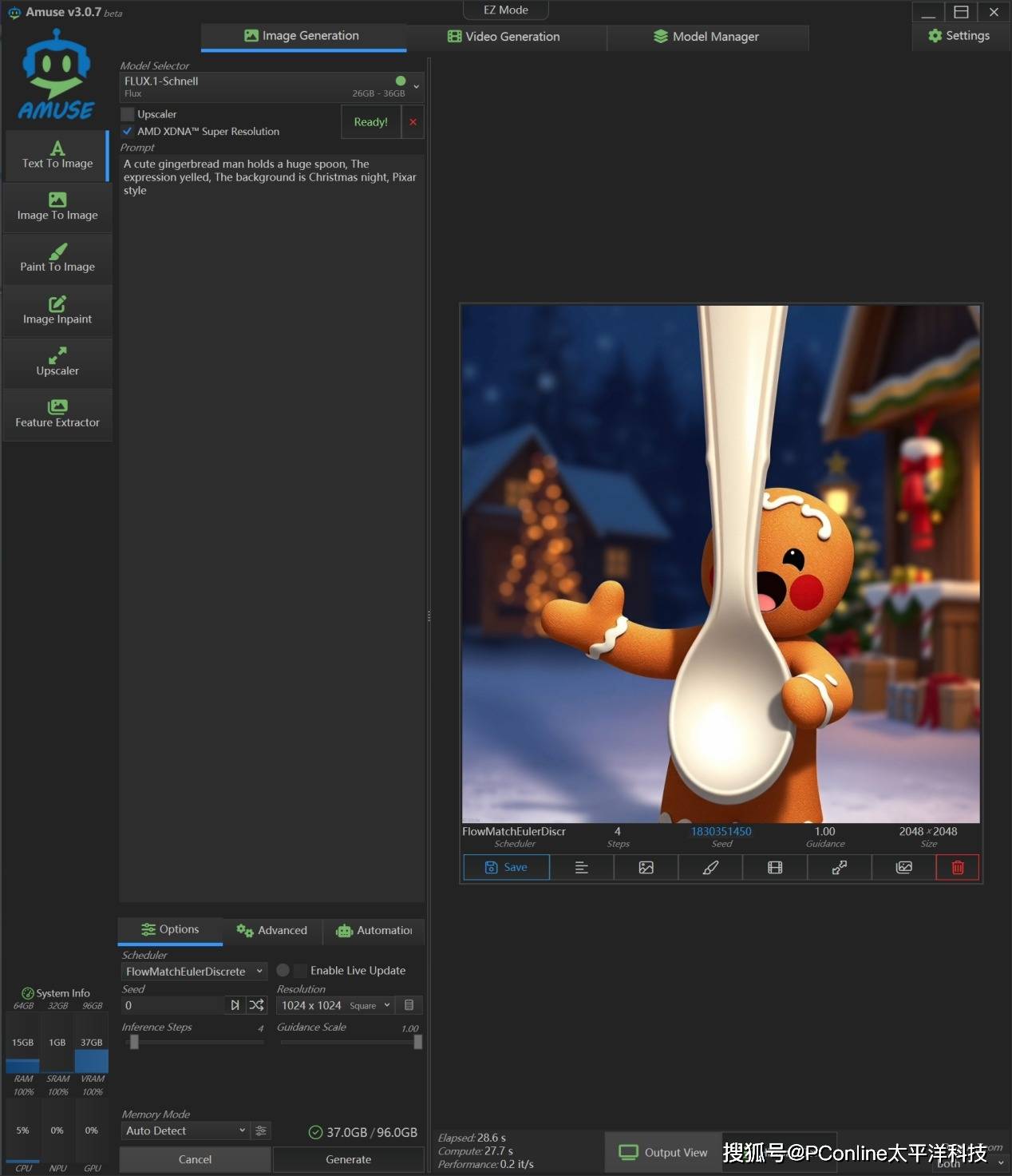
首先我们使用Flux.1-Schnell来进行文生图测试,生成 1024×1024 的图像并超分到 2048×2048,迭代步数为4步,我们得到了一张非常不错的图片。
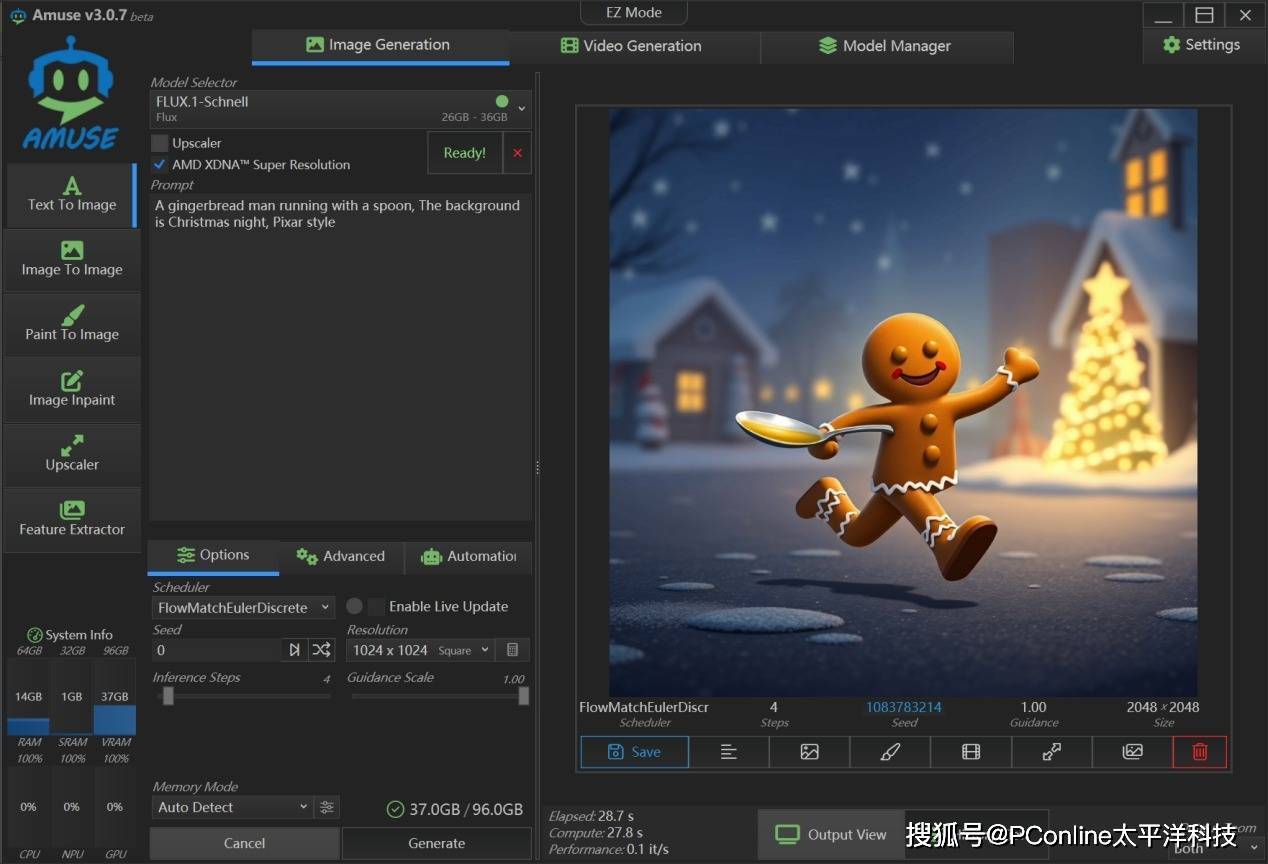
在生成“姜饼人卡通图”时,我们观察硬件表现,GPU占用率会频繁冲到100%,CPU平均占用率为4%,内存平均占用率为22%。在多次生成后,平均单张图像输出时间:28.7秒,性能指标:0.1 ~ 0.2 it/s。
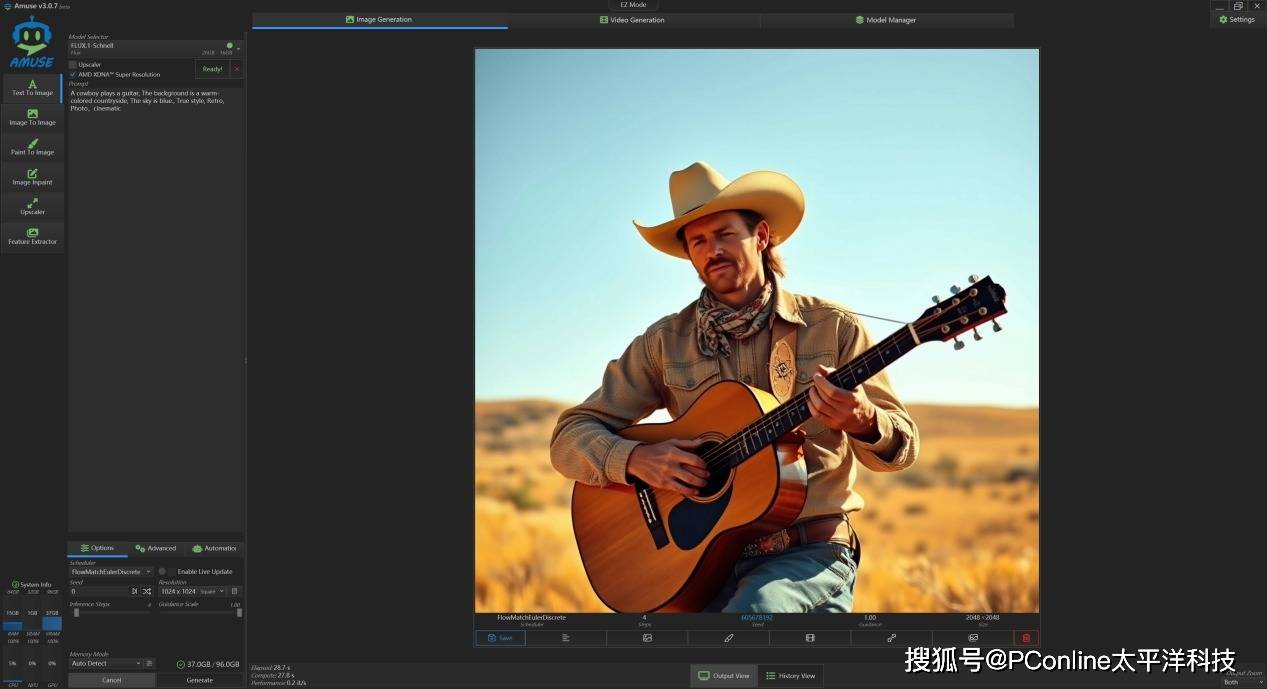
之后我们上一点强度,我们让Flux.1-Schnell进行写实风格“牛仔弹吉他”的照片,均成功生成,画面虽然有AI的痕迹,但符合我们的正常观感。
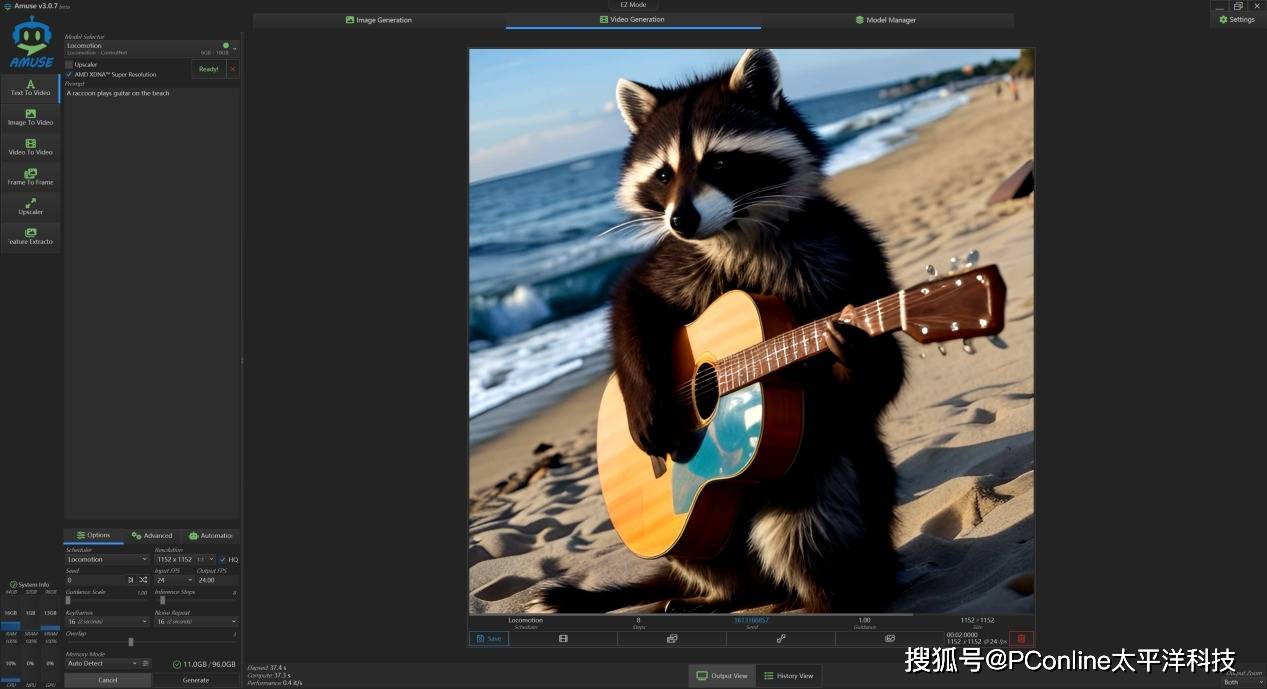
接下来我们更换为locomotion,来进行文生视频的测试,使用提示词“浣熊在沙滩上弹吉他”,分辨率1152x1152,生成2秒视频,输出时间:37.4秒,性能:0.4 it/s
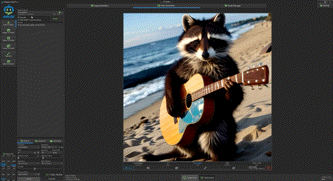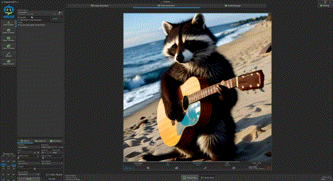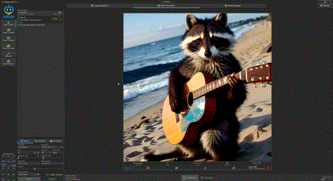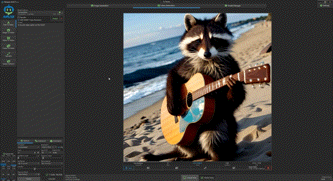
同样的,我们将视频生成指标调整为10秒,分辨率1152x1152,关键词同样是“浣熊在沙滩上弹吉他”,耗时204.7秒,吉他虽然略有浮动,但浣熊的效果可以接受。
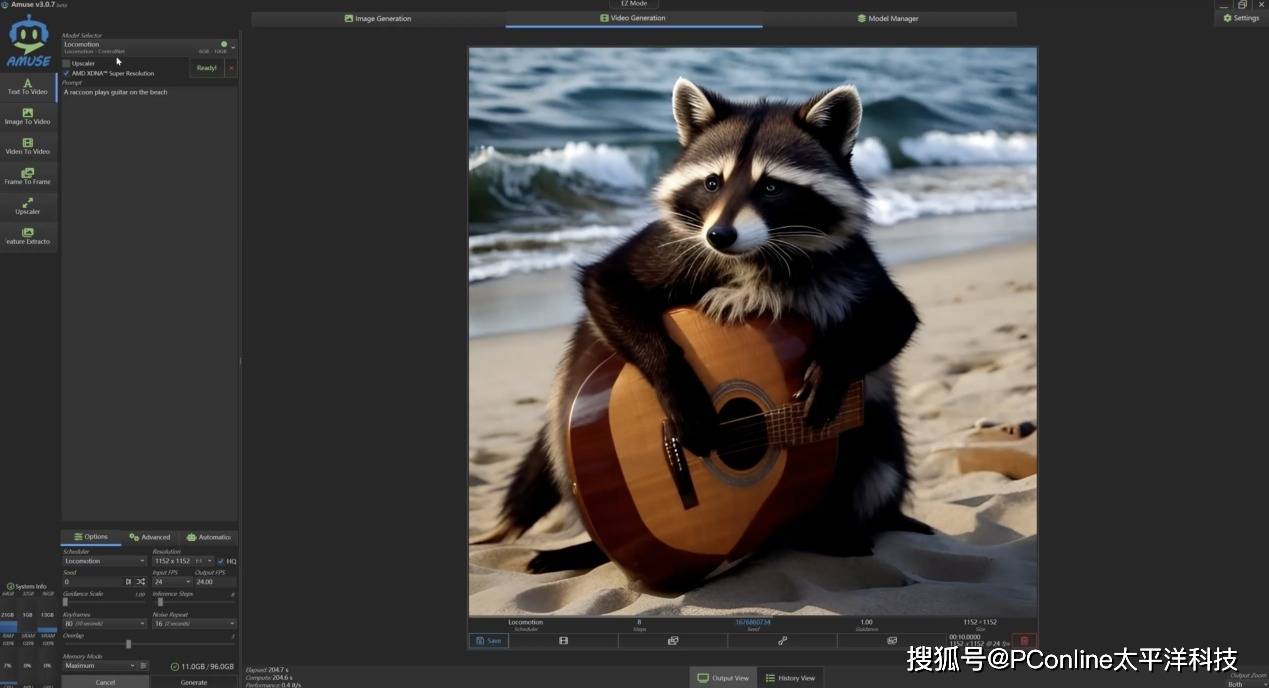

从图像到视频,EVO-X2 Mini 在面对这类计算量大、显存占用高的创意生成任务时依然保持了不错极高的稳定性和响应速度。无论是 Flux 快速出图时 GPU 的高效调用,还是 LOCOocomotion 在高分辨率视频生成中的持续输出表现,都离不开 AMD Ryzen 锐龙AI Max+ 395 架构下 CPU、GPU、NPU 三者的协同调度。
总结:一颗芯片带来的转变,从云端回到桌面
如果说过去我们总默认,大模型、尤其是几十亿甚至上百亿参数级别的 AI 模型,只能在云端大型服务器上运行,那极摩客 EVO-X2 Mini 的出现,无疑给出了一个颠覆性的答案。它不仅能把这些“高门槛任务”拉回到开发者的桌面,还让整个 AI 工作流变得更简单、更可控。

真正让这种转变成为可能的,是它所搭载的 AMD Ryzen 锐龙AI Max+ 395 APU。这颗芯片并不是单纯追求 CPU 或 GPU 性能的堆料式升级,而是通过全新的异构设计,把 Zen 5 高性能核心、RDNA 3.5 图形架构、以及 XDNA 2架构 NPU 融合为一个真正面向多模态 AI 的算力平台。它的 50+126 TOPS 总AI 推理能算力 和 统一共享的高带宽内存架构,让多模型并行、高负载任务不再是“顶配专属”。

在实际体验中,这不仅意味着可以运行 Qwen3 这样体量惊人的模型,或部署 DeepSeek、Flux、LOCOocomotion 等多模态生成任务,更意味着开发者可以在离线状态下完成训练、调试和原型设计,彻底摆脱云端限制与 Token 焦虑。这对于教育用户、小型团队甚至内容创作者来说,几乎相当于多年前“独立剪片”从工作站下放到笔记本那种解放感。
更关键的是,这不只是一台机器的偶然突破,而是 AMD AI PC 生态系统的一部分。除了 EVO-X2 Mini,后面我们还能见到更多搭载 Ryzen 锐龙AI Max+ 395 的设备桌面Mini AI工作站甚至是笔记本,相信它们将会覆盖从桌面端到移动端的完整本地 AI 应用场景。
AMD 正在让“本地 AI”从概念变成现实,不只是性能上的领先,更是开发范式的重构。对于那些想真正掌控算力、探索多模态 AI 应用的人来说,像极摩客 EVO-X2 Mini 这样的设备,正是一扇打开未来可能性的门。
































热门优惠券
更多-

- ROTHSCROOSTER旗舰店满49减16
- 有效期至: 2025-01-25
- 立即领取
-
- 萨布森旗舰店满1299减800
- 有效期至: 2025-01-17
- 立即领取
-
- 哲高玩具旗舰店满69减33
- 有效期至: 2025-01-05
- 立即领取
-
- 戴·可·思官方旗舰店满196减27
- 有效期至: 2025-04-01
- 立即领取
-
- 佳婴旗舰店满30减3
- 有效期至: 2025-01-10
- 立即领取
-
- ROTHSCROOSTER旗舰店满19减8
- 有效期至: 2025-01-25
- 立即领取
-
- 荣业官方旗舰店满20减10
- 有效期至: 2025-01-04
- 立即领取
-
- 戴·可·思(Dexter)母婴京东自营旗舰店满48减10
- 有效期至: 2025-01-12
- 立即领取
-
- KOKOROCARE旗舰店满158减100
- 有效期至: 2025-03-28
- 立即领取
-
- RODEL官方旗舰店满59减30
- 有效期至: 2025-01-02
- 立即领取