AI疯了!这个模型让所有IP角色同台飙戏
近日,有开发团队开源了一款全新的角色混合生成模型——MIMIX,实现了不同角色在场景中的自然交互与融合。

现阶段,文生视频已经较为成熟,Veo 3、Sora 等视频模型都能较好地完成文字到视频的转变,并实现简单的交互。
而 MIMIX 模型的出发点则是希望实现角色在不同的世界中自然互动,例如猫和老鼠进入憨豆先生的世界。其中的关键挑战就是在保持每个角色的身份和行为的同时,实现连贯的跨情境交互。既需要保证猫和老鼠的角色行为不变,又需要和憨豆先生在场景中发生自然且符合逻辑的交互。

不仅如此,现有 AI 存在的另一个问题,就是不同角色的混合很容易让 AI产生幻觉,导致风格发生变化,例如憨豆先生变成了猫和老鼠的动画风格。

为了解决这些问题,开发团队引入了一个框架,通过跨角色嵌入(CCE)来解决这些问题,它通过多模态来源学习身份和行为逻辑,以及跨角色增强(CCA),它通过合成共存和混合风格数据丰富训练。
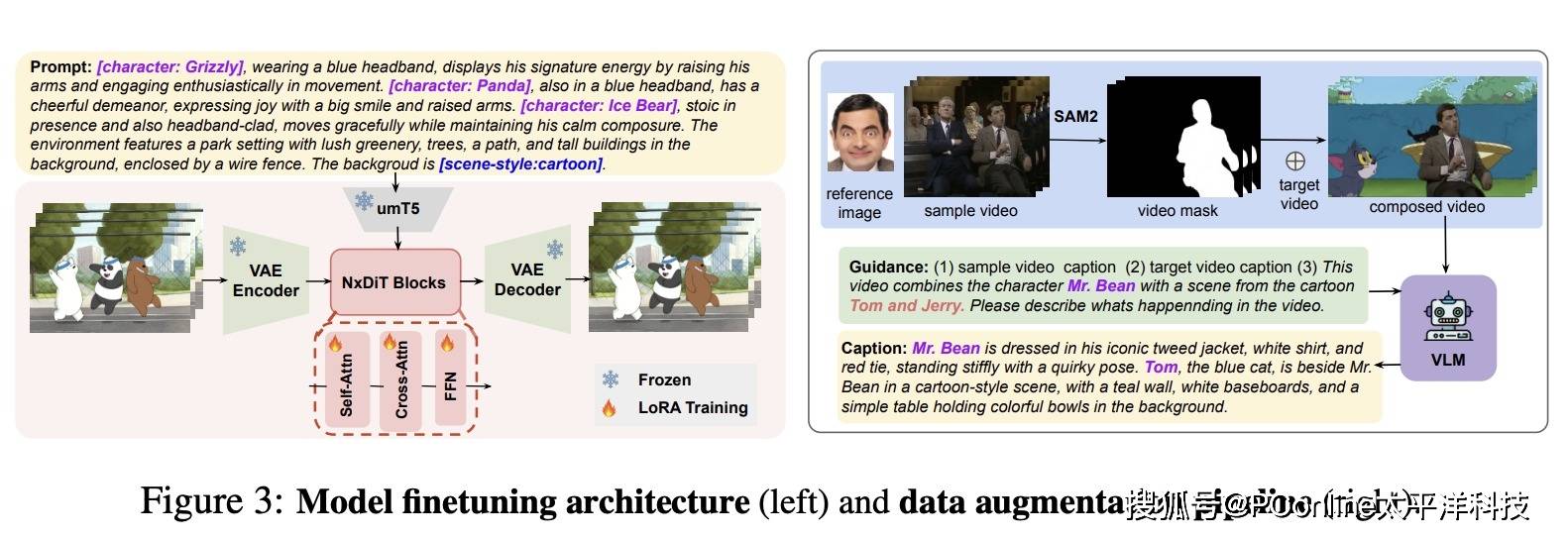
为了让角色保持风格,AI 需要学习大量的数据,要学习角色的外观形象、运动模式以及不同场景下的习惯,同时团队还设计了一套全新的格式来记录角色的身份,让角色和场景区分开来。有了这一全新的格式,在后续的推理过程中,AI 能够识别并维持角色的身份和行为习惯,而不受场景的影响。

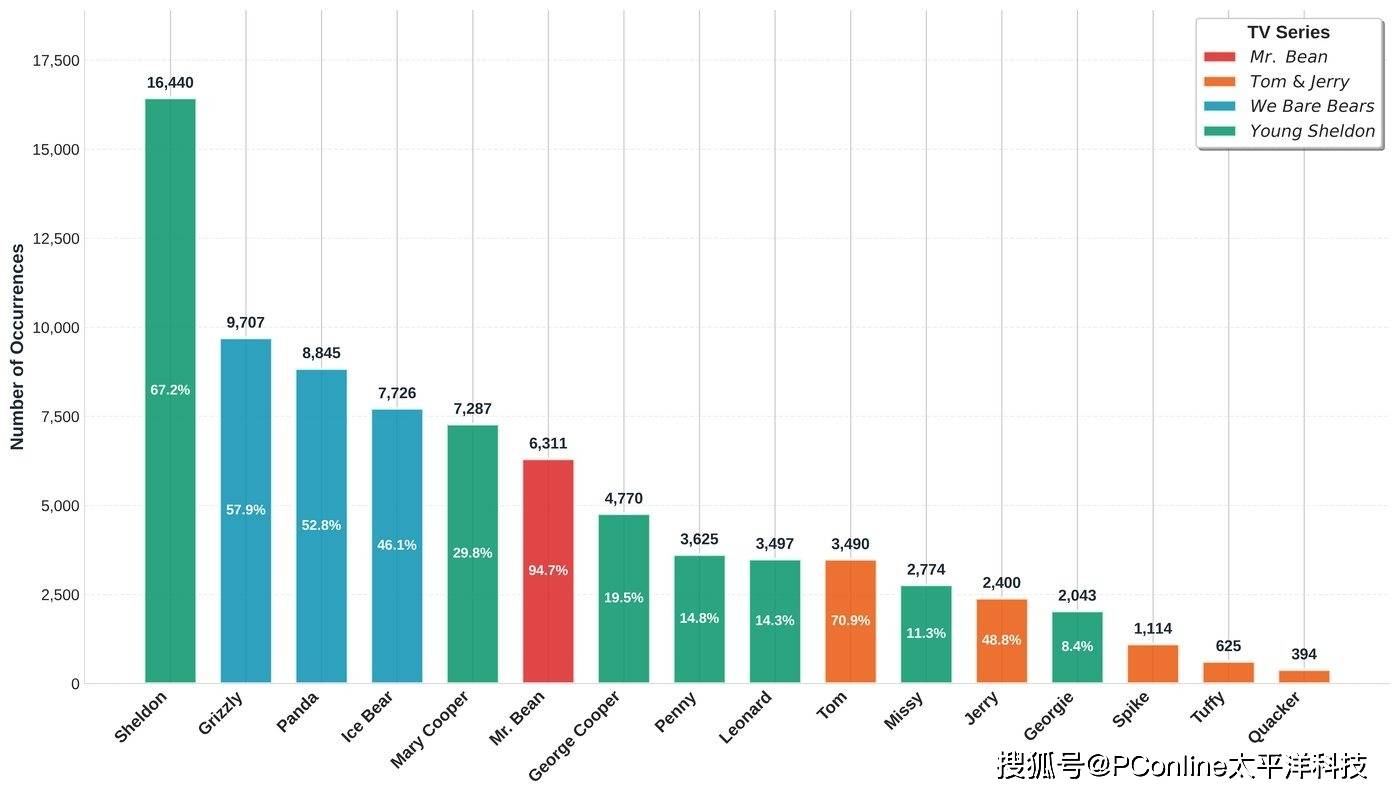
据了解,团队采集了4 部影视作品《憨豆先生》《汤姆和杰瑞》《我们裸熊》《小谢尔顿》81 小时的视频建立了数据集,对 52000 个片段、10 个角色进行了深度学习,通过标注角色和风格标签,实现了可控的多角色混合视频生成。
MIMIX 的出现,为影视作品的二次创作乃至原创内容的生成开启了无限的可能性。理论上,只要为模型提供足够的高质量训练数据,创作者就可以生成出媲美原作的高保真度二创视频,实现“关公战秦琼”式的奇妙构想。
当然,正如所有新兴技术一样,MIMIX 目前也面临着挑战。其效果在很大程度上依赖于大规模、精标注的训练数据。当可用的训练素材稀少时,其生成效果的稳定性是否会打折扣?此外,未来的发展方向必然是如何降低数据门槛。模型能否进化到直接从网络上的海量在线素材中进行自主学习和标注,从而实现多角色混合视频的快速、低成本生成?
我们有理由保持乐观。或许在不远的将来,随着模型的不断迭代与优化,普通用户将能够仅凭几张照片或一段简短的视频,就能让自己喜爱的角色出现在任何经典的影视场景中,甚至创造出一部完全由 AI 生成的、多角色互动的全新作品。MIMIX 已经为我们揭开了这扇大门的缝隙,门后的世界,值得我们共同期待。





























热门优惠券
更多-

- ROTHSCROOSTER旗舰店满49减16
- 有效期至: 2025-01-25
- 立即领取
-
- 萨布森旗舰店满1299减800
- 有效期至: 2025-01-17
- 立即领取
-
- 哲高玩具旗舰店满69减33
- 有效期至: 2025-01-05
- 立即领取
-
- 戴·可·思官方旗舰店满196减27
- 有效期至: 2025-04-01
- 立即领取
-
- 佳婴旗舰店满30减3
- 有效期至: 2025-01-10
- 立即领取
-
- ROTHSCROOSTER旗舰店满19减8
- 有效期至: 2025-01-25
- 立即领取
-
- 荣业官方旗舰店满20减10
- 有效期至: 2025-01-04
- 立即领取
-
- 戴·可·思(Dexter)母婴京东自营旗舰店满48减10
- 有效期至: 2025-01-12
- 立即领取
-
- KOKOROCARE旗舰店满158减100
- 有效期至: 2025-03-28
- 立即领取
-
- RODEL官方旗舰店满59减30
- 有效期至: 2025-01-02
- 立即领取